한국음악저작권협회는 음악 저작권 신규 신고 시 AI 사용 여부를 확인하는 절차를 도입했습니다.신고자는 AI를 사용하지 않았음을 보증해야 하며, 허위 신고 시 법적 책임을 지게 됩니다.
이는 AI를 활용한 음악 창작이 증가함에 따라 저작권 관련 법적 문제가 발생할 수 있다는 우려 때문입니다. 현행 저작권법상 AI가 생성한 콘텐츠는 저작물로 인정되지 않으며, 한음저협은 AI를 100% 사용한 음악의 등록을 거부하고 있습니다. 다만, AI를 일부 활용했더라도 인간의 창작적 기여가 있다면 저작물성을 인정할 수 있다는 입장입니다. 한음저협은 AI 활용 음악에 대한 명확한 기준과 관리 방안이 마련되지 않은 상황에서 이번 조치를 시행하게 되었다고 밝혔습니다.
알파고 등장 때만해도 AI 가 창의적인 분야는 어려울 것이란 생각이었는데, 기술의 발전은 정말 놀랍네요…
이번 한음저협의 조치는 AI 기술이 음악 창작 분야에 미치는 영향에 대한 중요한 논의를 촉발할 것으로 보입니다. AI 활용 음악에 대한 명확한 법적 기준과 관리 방안 마련이 시급하며, 이는 창작자의 권리 보호와 음악 산업 발전을 위해 필수적입니다. AI 기술의 발전 속도를 고려할 때, 앞으로 더욱 다양한 형태의 AI 활용 음악이 등장할 것이며, 이에 대한 지속적인 논의와 제도적 보완이 필요합니다.
“금융 특화 ‘한글 말뭉치’ 공유…생성형 AI 개발 돕는다”
금융위원회는 국내 금융권에 특화된 인공지능(AI) 서비스 개발을 지원하기 위해 ‘금융 특화 한글 말뭉치’를 무료로 제공합니다.
이 말뭉치는 금융 전문 용어와 법규, 제도 등을 포함한 대규모 한국어 언어 자료 집합으로, AI 모델의 금융 지식 학습, 답변 정확도 향상, 성능 및 윤리 평가에 활용됩니다. 2025년 6월 말까지 진행되는 시범사업 기간 동안 총 1만2600건, 약 45GB 규모의 말뭉치가 제공되며, 이를 통해 금융 AI 서비스의 환각 및 편향 문제를 해소하고 금융 소비자 보호를 강화할 수 있을 것으로 기대됩니다.
국내 금융 환경에 최적화된 AI 서비스 개발로 금융 분야 전문성 부족 문제를 해결하고, 보다 정확하고 신뢰할 수 있는 금융 서비스를 가능하게 해주면 좋겠네요.
“경량 AI: 인공지능 모델 경량화의 기본 개념과 최근 연구사례 및 시사점”
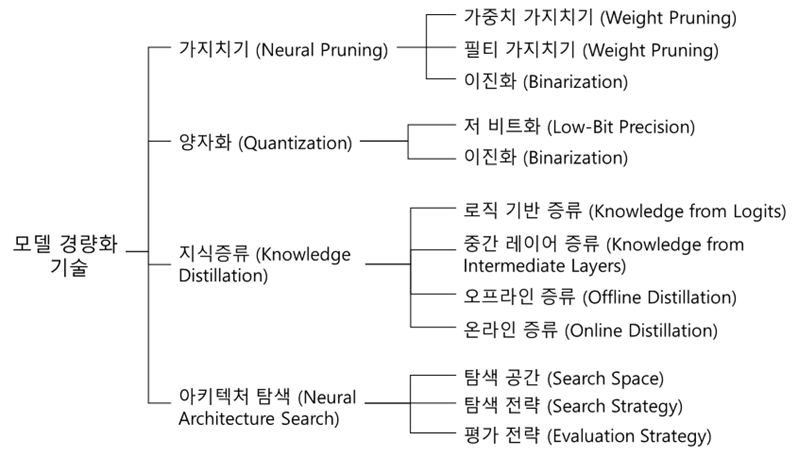
최근 AI 분야는 거대 파라미터를 갖는 언어 모델에 초점이 맞춰지면서, 높은 성능을 보이는 반면 연산 비용과 저장 공간이 급격히 증가하는 추세입니다. 이러한 문제를 해결하기 위해 AI 모델 경량화 기술이 주목받고 있으며, 이는 모델의 크기를 줄이고 연산 효율을 높여 컴퓨터 자원 낭비를 방지하고 에너지 소비를 최소화하면서도 기존 모델과 유사한 성능을 유지하는 것을 목표로 합니다.
주요 경량화 기법으로는 뉴럴 프루닝(Neural Pruning), 지식증류(Knowledge Distillation), 양자화(Quantization), 아키텍처 탐색(Neural Architecture Search) 등이 있습니다. 이러한 기술들은 모바일 및 엣지 디바이스와 같이 연산 자원이 제한된 환경에서 AI 모델을 효율적으로 실행하는 데 필수적이며, 실시간 추론 속도가 중요한 자율주행 차량, 챗봇, 음성 비서, CCTV 등 다양한 분야에서 활용되고 있습니다.
특히, 딥시크(DeepSeek)는 오픈소스 추론모델인 딥시크-R1을 공개하며 저비용·고효율의 경량 AI 시대를 예고하여 글로벌 AI 시장에 큰 영향을 주고 있습니다. 이는 기존 대형 모델에 준하는 성능을 약 1/20 수준의 저렴한 비용으로 구현해 주목받고 있습니다.
AI 모델 경량화 기술이 자원 효율성을 높이고 다양한 환경에서 AI 적용 가능성을 확대하는 데 중요한 역할을 할 것으로 전망하며, 향후 Physics AI와 같은 분야에서 실시간성과 효율성을 갖춘 AI 모델 설계에 대한 관심이 더욱 높아질 것으로 예상합니다.
“대규모 언어모델로 신소재 합성 가능성 예측·해석하는 기술 개발”
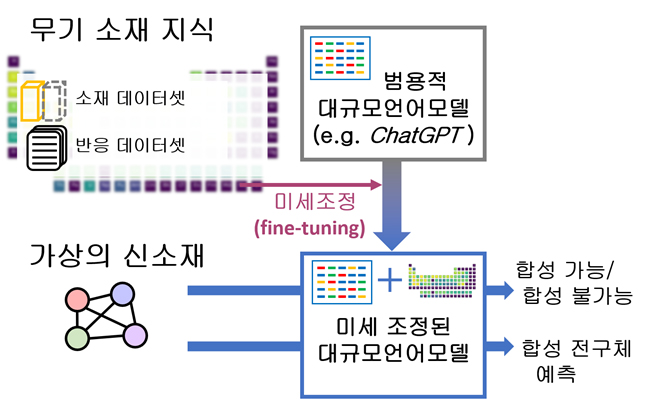
서울대학교 정유성 교수 연구팀이 대규모 언어 모델(LLM)을 활용하여 새로운 물질의 합성 가능성을 예측하고 해석하는 기술을 개발했다는 내용입니다. 이 기술은 기존의 머신러닝 모델보다 높은 예측 정확도를 보이며, 합성 가능성에 영향을 미치는 요인에 대한 해석도 제공합니다.
이 연구는 새로운 물질의 개발을 가속화하고, 특히 반도체 및 이차전지 산업에서 활용될 것으로 기대됩니다.
# 먼저 필요한 라이브러리가 설치되어 있어야 합니다:
# pip install torch diffusers transformers
import torch
from diffusers import StableDiffusionPipeline
# M1 CPU에서 실행하도록 설정 (MPS 사용 가능 시 활용)
device = "mps" if torch.backends.mps.is_available() else "cpu"
# Stable Diffusion 모델 로드
model_id = "runwayml/stable-diffusion-v1-5"
pipe = StableDiffusionPipeline.from_pretrained(model_id)
pipe = pipe.to(device)
# 프롬프트 설정
prompt = "A cute cat swimming in space"
# 이미지 생성
image = pipe(prompt).images[0]
# 이미지 저장
image.save("test_image.png")
<결과>
macos m1 32GB 메모리에서 최소 사양으로 Diffusion 모델을 이용하여 간단하게 이미지 생성하는 방법을 살펴 보았습니다.
LCEL은 LangChain Expression Language의 약어인데 기본적인 방식으로 Chain을 사용해도 문제가 없지만 코드를 좀 더 간략하게 사용하고 병렬처리, 비동기, 스트리밍 기능을 제공하기 위해 LCEL을 사용한다.
LCEL은 LangChain 라이브러리에서 복잡한 LLM(Large Language Model) 애플리케이션을 구축하기 위한 선언적 인터페이스로, 코드의 간결성과 유지보수성을 극대화하도록 설계되었습니다. 파이썬의 “|” 연산자를 활용해 컴포넌트를 직관적으로 연결하는 방식이 특징입니다
사용자 정의 체인을 가능한 쉽게 만들 수 있도록 구현된 Runnable 프로토콜은 대부분의 컴포넌트에 구현되어 있습니다. 이는 표준 인터페이스로, 사용자 정의 체인을 정의하고 표준 방식으로 호출하는 것을 쉽게 만듭니다. 표준 인터페이스에는 다음이 포함됩니다.
stream: 응답의 청크를 스트리밍합니다.
invoke: 입력에 대해 체인을 호출합니다.
batch: 입력 목록에 대해 체인을 호출합니다.
stream: 실시간 출력
이 함수는 chain.stream 메서드를 사용하여 주어진 토픽에 대한 데이터 스트림을 생성하고, 이 스트림을 반복하여 각 데이터의 내용(content)을 즉시 출력합니다. end=”” 인자는 출력 후 줄바꿈을 하지 않도록 설정하며, flush=True 인자는 출력 버퍼를 즉시 비우도록 합니다.
from langchain.prompts import ChatPromptTemplate
from langchain_ollama import ChatOllama
from langchain_core.output_parsers import StrOutputParser
llm_model = ChatOllama(model="exaone3.5", streaming=True, temperature=0)
prompt = ChatPromptTemplate.from_template("{topic}를(을) 1문장으로 간락하게 설명해줘")
# 1. LCEL 체인 구성
chain = prompt | llm_model | StrOutputParser()
# 2. 스트리밍 실행
input_topic = {"topic": "인공지능"}
for chunk in chain.stream(input_topic):
print(chunk, end="", flush=True) # 실시간 출력 유지
print()
인공지능은 컴퓨터 시스템이 인간의 지능을 모방하여 학습, 문제 해결, 의사결정 등을 수행할 수 있도록 설계된 기술입니다.
invoke: 호출
chain 객체의 invoke 메서드는 주제를 인자로 받아 해당 주제에 대한 처리를 수행합니다.
# 3. invoke 실행
result = chain.invoke({"topic": "인공지능"})
print(result)
인공지능은 컴퓨터 시스템이 인간의 지능을 모방하여 학습, 문제 해결, 의사결정 등을 수행할 수 있도록 설계된 기술입니다.
# 4. batch 실행
inputs = [
{"topic": "인공지능"},
{"topic": "IoT"},
{"topic": "블록체인"}
]
results = chain.batch(inputs) # 병렬 처리
print(results)
[‘인공지능은 컴퓨터 시스템이 인간의 지능을 모방하여 학습, 문제 해결, 의사결정 등을 수행할 수 있도록 설계된 기술입니다.’, ‘IoT는 인터넷을 통해 다양한 기기들이 서로 연결되어 데이터를 주고받으며 효율적으로 작동하도록 하는 기술입니다.’, ‘블록체인은 분산된 데이터베이스로, 거래 기록을 안전하고 투명하게 저장하여 중앙 관리 기관 없이도 신뢰성을 유지합니다.’]
max_concurrency 매개변수를 사용하여 동시 요청 수를 설정할 수 있습니다
config 딕셔너리는 max_concurrency 키를 통해 동시에 처리할 수 있는 최대 작업 수를 설정합니다. 여기서는 최대 3개의 작업을 동시에 처리하도록 설정되어 있습니다.
result = chain.batch (
[
{"topic": "지구의 자전 속도는?"},
{"topic": "달의 자전 속도는?"},
{"topic": "말의 달리기 속도는?"},
{"topic": "지구를 탈출 하기 위한 최소 속도는?"},
],
config={"max_concurrency": 2},
)
print(result)ㅇㄹ
[‘지구는 약 24시간에 걸쳐 자전하여 하루를 만듭니다.’, ‘달의 자전 속도는 약 1달(27.3일)에 걸쳐 지구를 한 바퀴 돌면서 동일한 면을 보이는 것으로, 이는 자전 주기와 공전 주기가 일치하는 상태입니다.’, ‘말의 달리기 속도는 종에 따라 다르지만, 일반적으로 경주마는 시속 55km에서 최고 시속 70km까지 달릴 수 있습니다.’, ‘지구 탈출을 위한 최소 속도는 탈출 속도로 약 11.2 km/s입니다.’]
Parallel: 병렬성
LangChain Expression Language가 병렬 요청을 지원하는 방법을 살펴봅시다. 예를 들어, RunnableParallel을 사용할 때(자주 사전 형태로 작성됨), 각 요소를 병렬로 실행합니다.
langchain_core.runnables 모듈의 RunnableParallel 클래스를 사용하여 두 가지 작업을 병렬로 실행하는 예시를 보여줍니다.
ChatPromptTemplate.from_template 메서드를 사용하여 주어진 country에 대한 수도 와 면적 을 구하는 두 개의 체인(chain1, chain2)을 만듭니다. 이 체인들은 각각 model과 파이프(|) 연산자를 통해 연결됩니다. 마지막으로, RunnableParallel 클래스를 사용하여 이 두 체인을 capital와 area이라는 키로 결합하여 동시에 실행할 수 있는 combined 객체를 생성합니다.
chain1.invoke() 함수는 chain1 객체의 invoke 메서드를 호출합니다.
이때, country이라는 키에 대한민국라는 값을 가진 딕셔너리를 인자로 전달합니다.
from langchain_ollama import ChatOllama
from langchain_core.prompts import PromptTemplate
from langchain_core.output_parsers import StrOutputParser
from langchain_core.runnables import RunnableParallel
llm_model = ChatOllama(model="exaone3.5", temperature=0)
# {country} 의 수도를 물어보는 체인을 생성합니다.
chain1 = (
PromptTemplate.from_template("{country} 의 수도는 어디야?")
| llm_model
| StrOutputParser()
)
# {country} 의 면적을 물어보는 체인을 생성합니다.
chain2 = (
PromptTemplate.from_template("{country} 의 면적은 얼마야?")
| llm_model
| StrOutputParser()
)
combined = RunnableParallel(capital=chain1, area=chain2)
# chain1 를 실행합니다.
result = chain1.invoke({"country": "대한민국"})
print(result)
대한민국의 수도는 서울입니다.
이번에는 chain2.invoke() 를 호출합니다. country 키에 다른 국가인 미국 을 전달합니다.
# chain2 를 실행합니다.
result = chain2.invoke({"country": "한국"})
print(result)
한국의 면적은 약 **100,363 제곱킬로미터**입니다. 이는 대략적으로 **남한**의 면적을 의미하며, **북한**을 포함하면 약 **220,847 제곱킬로미터** 정도입니다. 더 자세한 정보가 필요하시면 알려주세요! 😊
combined 객체의 invoke 메서드는 주어진 country에 대한 처리를 수행합니다. 이 예제에서는 대한민국라는 주제를 invoke 메서드에 전달하여 실행합니다.
# combined 를 실행합니다.
result = combined.invoke({"country": "한국"})
print(result)
{‘capital’: ‘한국의 수도는 서울입니다.’, ‘area’: ‘한국의 면적은 약 **100,363 제곱킬로미터**입니다. \n\n이는 대략적으로 **남한**의 면적을 의미하며, **북한**을 포함하면 약 **220,847 제곱킬로미터** 정도입니다. \n\n더 자세한 정보가 필요하시면 알려주세요! 😊’}
배치에서의 병렬 처리
병렬 처리는 다른 실행 가능한 코드와 결합될 수 있습니다. 배치와 병렬 처리를 사용해 보도록 합시다.
chain1.batch 함수는 여러 개의 딕셔너리를 포함하는 리스트를 인자로 받아, 각 딕셔너리에 있는 “topic” 키에 해당하는 값을 처리합니다. 이 예시에서는 “대한민국”와 “미국”라는 두 개의 토픽을 배치 처리하고 있습니다.
# chain1 를 실행합니다.
result = chain1.batch([{"country": "대한민국"}, {"country": "미국"}])
print(result)
[‘대한민국의 수도는 서울입니다.’, ‘미국의 수도는 워싱턴 D.C.입니다.’]
chain2.batch 함수는 여러 개의 딕셔너리를 리스트 형태로 받아, 일괄 처리(batch)를 수행합니다. 이 예시에서는 대한민국와 미국라는 두 가지 국가에 대한 처리를 요청합니다.
# chain2 를 실행합니다.
result = chain2.batch([{"country": "대한민국"}, {"country": "미국"}])
print(result)
[‘대한민국의 면적은 약 **100,363 제곱킬로미터**입니다.’, ‘미국의 면적은 약 **9,833,520 제곱 킬로미터 (km2)** 입니다. 이는 세계에서 **세 번째로 큰 나라**입니다. \n\n혹시 다른 단위로 알고 싶으신가요? 예를 들어, 제곱 마일로 알고 싶으시다면 약 **3.7 백만 제곱 마일**입니다.’]
combined.batch 함수는 주어진 데이터를 배치로 처리하는 데 사용됩니다. 이 예시에서는 두 개의 딕셔너리 객체를 포함하는 리스트를 인자로 받아 각각 대한민국와 미국 두 나라에 대한 데이터를 배치 처리합니다.
# combined 를 실행합니다.
result = combined.batch([{"country": "대한민국"}, {"country": "미국"}])
print(result)
[{‘capital’: ‘대한민국의 수도는 서울입니다.’, ‘area’: ‘대한민국의 면적은 약 **100,363 제곱킬로미터**입니다.’}, {‘capital’: ‘미국의 수도는 워싱턴 D.C.입니다.’, ‘area’: ‘미국의 면적은 약 **9,833,520 제곱 킬로미터 (km2)** 입니다. 이는 세계에서 **세 번째로 큰 나라**입니다. \n\n혹시 다른 단위로 알고 싶으신가요? 예를 들어, 제곱 마일로 알고 싶으시다면 약 **3.7 백만 제곱 마일**입니다.’}]
LangChain은 LLM 기반 어플리케이션 개발을 위한 프레임워크로써, 다양한 LLM관련 기능들을 결합(체인)하여 손쉽게 사용하도록 지원합니다. 해리슨 체이스(Harrison Chase)가 2022년 Robust Intelligence 근무 시절 시작한 오픈소스 프로젝트, JavaScript와 파이썬에서 패키지 형식으로 만들었습니다.
LangChain은 대규모 언어 모델(LLM)을 기반으로 한 애플리케이션을 개발하기 위한 오픈 소스 프레임워크입니다. 이 혁신적인 도구는 개발자들이 AI 기반 애플리케이션을 더욱 효과적이고 유연하게 구축할 수 있도록 지원합니다.
LangChain의 주요 구성 요소와 관련 도구를 아래와 같이 소개합니다.
1) LangChain의 주요 구성 요소
1.1) LLMs (Large Language Models)
LangChain의 중심에는 LLM이 있습니다. 이들은 자연어 처리(NLP) 작업을 수행하며, 텍스트 생성, 번역, 질문 응답 등 다양한 기능을 제공합니다. LangChain은 OpenAI, Hugging Face, Ollama 등 다양한 LLM과 통합될 수 있습니다.
1.2) Prompt Templates
프롬프트 템플릿은 사용자의 입력을 모델이 이해할 수 있는 형식으로 변환하는 데 사용됩니다. 이를 통해 모델에 명확한 지시를 제공하거나 특정 작업의 맥락을 설정할 수 있습니다.
예시:
사용자 이름과 질문을 포함하는 챗봇 프롬프트
특정 데이터 요약을 요청하는 템플릿
1.3) Chains
체인은 여러 작업을 연결하여 복잡한 프로세스를 자동화하는 LangChain의 핵심 개념입니다. 체인은 사용자 입력에서 시작하여 모델 출력에 이르는 일련의 단계를 정의합니다.
구성:
Links: 체인을 구성하는 개별 작업 단위로, 입력 데이터를 처리하고 다음 단계로 전달합니다.
예시 체인: 데이터 검색 → LLM 호출 → 출력 포맷팅
1.4) Retrievers & Indexes
Retrievers: 사용자의 질의에 따라 적절한 문서를 검색하는 인터페이스입니다.
Indexes: 문서와 메타데이터를 저장하는 데이터베이스로, 검색 및 처리를 효율적으로 수행할 수 있도록 지원합니다.
1.5) Vector Stores
벡터 스토어는 텍스트 데이터를 벡터화하여 저장하고 검색하는 데 사용됩니다. 이를 통해 자연어 검색 및 유사성 기반 검색이 가능합니다.
예시:
Pinecone, Weaviate, FAISS와 같은 벡터 데이터베이스 통합
1.6) Agents
에이전트는 고수준의 지시를 바탕으로 적절한 도구(체인, API 등)를 선택하고 실행합니다. 이를 통해 동적인 작업 흐름을 구현할 수 있습니다.
예시:
사용자의 요청에 따라 데이터 검색 후 번역 수행
여러 LLM 간 협업 처리
1.7) Memory
LangChain은 대화형 애플리케이션에서 이전 상호작용 정보를 기억할 수 있는 메모리 기능을 제공합니다. 이를 통해 컨텍스트를 유지하며 사용자 경험을 개선할 수 있습니다
2) LangChain 관련 도구 및 확장
2.1) LangSmith
LangSmith는 LLM Chain을 디버깅, 테스트, 평가 및 모니터링할 수 있는 개발자 플랫폼으로 LangChain 애플리케이션의 디버깅 및 성능 추적 도구입니다.
실행 기록 추적 및 시각화를 지원하여 체인의 작동 방식을 분석할 수 있습니다.
모델 성능 평가 및 최적화를 위한 데이터를 제공합니다.
2.1) LangServe
LangServe는 LangChain 객체와 체인을 REST API로 배포할 수 있도록 돕는 라이브러리입니다.
FastAPI와 통합되어 API 엔드포인트(/invoke, /stream 등)를 제공합니다.
입력 및 출력 스키마를 자동으로 유추하며 데이터 유효성을 검증합니다.
스트리밍 출력과 중간 단계를 확인할 수 있는 플레이그라운드 페이지를 제공합니다.
2.3) LangChain Templates
LangChain Templates는 쉽게 배포 가능한 참조 아키텍처 모음입니다.
사전 정의된 체인과 에이전트를 제공하여 빠르게 애플리케이션을 구축할 수 있습니다.
템플릿은 표준 형식으로 제공되며, LangServe를 통해 쉽게 배포 가능합니다.
LangChain은 LLM 기반 애플리케이션 개발의 복잡성을 줄이고, 강력하면서도 유연한 솔루션을 제공합니다. 이를 통해 AI 기술을 다양한 산업 분야에 효과적으로 적용할 수 있습니다.
챗봇 및 가상 비서: 다국어 지원, 사용자 맞춤형 응답 제공
지식 검색 시스템: 대규모 문서 데이터베이스에서 정보 검색
데이터 요약 및 분석: 긴 문서를 요약하거나 데이터 패턴 분석
자동화된 번역 서비스: 다양한 언어 간 번역 및 포맷팅
이러한 LangChain을 이용한 LLM 개발은 여러가지 장점을 가지고 있습니다.
1) 유연성: 각 구성 요소가 독립적으로 설계되어 재사용성과 확장성이 높으며, 다양한 언어 모델과 데이터 소스를 쉽게 통합할 수 있습니다.
2) 확장성: 외부 데이터 소스 및 시스템과 쉽게 연결 가능하며, 새로운 기능을 지속적으로 추가하고 있어 빠르게 발전하는 AI 생태계에 대응할 수 있습니다.
3) 커뮤니티 지원: 활발한 오픈 소스 커뮤니티의 지원을 받고 있어 지속적인 개선과 문제 해결이 가능합니다.
최근 몇 년간 대규모 언어 모델(LLM, Large Language Model)은 자연어 처리(NLP) 분야에서 혁신적인 변화를 이끌어왔습니다. ChatGPT, Bard, Claude와 같은 상용 LLM은 놀라운 성능을 제공하지만, 대부분의 경우 사용자는 높은 비용을 지불해야 합니다. 이러한 비용 문제는 특히 스타트업, 개인 개발자, 소규모 연구팀에게 부담으로 작용할 수 있습니다.
이에 따라 무료 또는 최소한의 비용으로 LLM을 개발하거나 활용하려는 움직임이 점점 더 주목받고 있습니다. 오픈소스 모델을 활용하여 LLM을 개발하는 방법과 그 이점, 그리고 이를 통해 얻을 수 있는 가능성에 대해 깊이 탐구해보고자 합니다.
1. 왜 무료 또는 저비용 LLM 개발이 필요한가?
1) 비용 절감
상용 LLM은 API 호출당 비용이 발생하며, 대규모 데이터 처리나 반복적인 작업이 필요한 경우 비용이 기하급수적으로 증가합니다. 예를 들어, 한 달 동안 수백만 번의 API 호출을 하는 애플리케이션은 수천 달러 이상의 비용이 들 수 있습니다. 반면 오픈소스 모델은 초기 설정 비용만 발생하며, 이후에는 클라우드 또는 로컬 서버에서 실행하여 지속적인 비용을 줄일 수 있습니다.
2) 커스터마이징 가능
상용 모델은 제한된 커스터마이징 옵션을 제공하며, 특정 도메인에 맞춘 튜닝이 어려울 수 있습니다. 반면 오픈소스 모델은 코드와 가중치가 공개되어 있어 특정 산업이나 애플리케이션에 맞게 조정할 수 있습니다.
3) 데이터 프라이버시
상용 LLM을 사용할 경우 데이터가 외부 서버로 전송되며, 이는 민감한 정보를 다루는 프로젝트에서 보안 리스크를 초래할 수 있습니다. 오픈소스 모델은 로컬 환경에서 실행 가능하므로 데이터 프라이버시를 보장할 수 있습니다.
2. 무료 또는 저비용 LLM 개발의 주요 접근 방식
본 블로그에서는 대표적인 무료 LLM 모델을 활용합니다.
LLaMA: Meta에서 공개한 모델로, 높은 성능과 효율성을 자랑합니다.
Exaone: LG전자 연구원에서 개발한 LLM 모델로 경량화 및 최적화 기술 연구에 집중했습니다.실제 산업 현장에서 사람의 생산성과 업무 효율성을 극대화할 수 있도록 성능을 강화했습니다.
Bloom: BigScience 프로젝트에서 개발한 다국어 지원 오픈소스 모델로, 다양한 언어와 도메인에 적합합니다.
Falcon: TII(Tecnhology Innovation Institute)에서 공개한 고성능 언어 모델로, 상업적 사용도 허용됩니다.
GPT-NeoX: EleutherAI에서 개발한 GPT 계열의 오픈소스 모델로, 성능과 확장성이 뛰어납니다.
이 기사는 대규모 언어 모델(LLM)을 사용하여 데이터가 많지 않은 경우 NER 모델을 학습하는 방법에 대해 논의합니다.
<출처 블로그>
몇 가지 예제 엔티티 목록을 사용하여 NER 데이터 세트를 생성하는 프로세스를 설명합니다. 이 프로세스에는 1) Few Shot 엔티티 목록을 만드는 것, 2) GPT-3를 사용하여 이를 확장하는 것, 3) GPT-3를 사용하여 NER 데이터 세트를 생성하는 것, 4) 그리고 이 생성된 데이터로 BERT 모델을 학습하는 것이 포함됩니다.
저자는 호텔 도메인을 예로 사용하여 5개의 엔티티 클래스를 정의하고, 클래스당 100개의 예제를 생성했습니다. 결과는 검증 데이터에서 유망한 성능을 보여주었습니다.
이 방법에서 두 가지만 변경하여 실행한 학습 코드와 추가로 분류 코드를 제공하고자 합니다. LLM을 활용하여 데이터셋을 자동 확장한 좋은 방법이라 생각됩니다. 1) GPT대신 한국어 무료 모델 Exaone3.5 모델 적용. 2) GPU 대신 CPU 실행
학습 코드
import re
import ollama
import numpy as np
import torch
import itertools
import torch.nn.functional as F
from tqdm import tqdm
from seqeval.scheme import IOB2
from transformers import AutoTokenizer, AutoModelForTokenClassification
from sklearn.metrics import f1_score
from seqeval.metrics import f1_score as ner_f1_score
real_entities = [
{
'class_name': '인명',
'entity_names': [
'홍길동',
'이순신',
'강감찬',
'이승만',
'이율곡'
]
},
{
'class_name': '지명',
'entity_names': [
'대한민국',
'서울특별시',
'강남구',
'삼성동',
'음성읍',
]
},
{
'class_name': '시간',
'entity_names': [
'2025년',
'3월',
'25일',
'10시',
'2025년 3월 25일 10시 25분 30초'
]
},
{
'class_name': '기업',
'entity_names': [
'삼성전자',
'SK하이닉스',
'포스코',
'이마트',
'GS리테일'
]
},
{
'class_name': '질병',
'entity_names': [
'식도역류증',
'위염',
'과민성 대장 증후군',
'감기',
'당뇨병'
]
}
]
def generate(prompt, model='exaone3.5', max_tokens=512):
# Ollama's generate method
response = ollama.generate(
model=model,
prompt=prompt,
options={"max_tokens": max_tokens}
)
# Extract the response text
return response['response']
def construct_entity_prompt(class_name, entity_names, k=10):
prompt = f'<{class_name}> 개의 엔터티 이름이 있습니다. {k}개의 새로운 <{class_name}> 엔터티 이름을 생성합니다.\n\n'
prompt += 'Entity names:\n'
for e in entity_names:
prompt += f'- {e}\n'
prompt += '\nGenerated names:\n-'
return prompt
def postprocess_entities(synthetic_entities):
processed = []
for ents in synthetic_entities:
ents = ents.split('\n')
for e in ents:
if '- ' in e: # Process only valid entries
processed.append(e.split('- ')[1].strip())
return processed
synthetic_entities = []
for real_ent in tqdm(real_entities):
class_name, entity_names = real_ent['class_name'], real_ent['entity_names']
prompt = construct_entity_prompt(class_name, entity_names)
syn_entities = generate(prompt)
syn_entities = postprocess_entities([syn_entities])
syn_entities = list(set(syn_entities)) # Remove duplicates
synthetic_entities.append({'class_name': class_name, 'entity_names': syn_entities})
all_entities = []
for real, synthetic in zip(real_entities, synthetic_entities):
all_entities.append({
'class_name': real['class_name'],
'entity_names': list(set(real['entity_names'] + synthetic['entity_names']))
})
def sample_entities(all_entities, min_k=1, max_k=3):
k = np.random.randint(min_k, max_k + 1)
idxs = np.random.choice(range(len(all_entities)), size=k, replace=False)
entities = []
for i in idxs:
ents = all_entities[i]
name = np.random.choice(ents['entity_names'])
entities.append({'class_name': ents['class_name'], 'entity_name': name})
return entities
def construct_sentence_prompt(entities, style='dialog'):
prompt = f'엔터티를 포함하는 {style} 문장을 생성합니다.\n\n'
entities_string = ', '.join([f"{e['entity_name']}({e['class_name']})" for e in entities])
prompt += f'엔터티: {entities_string}\n'
prompt += 'Sentence:'
return prompt
def construct_labels(generated, entities, class2idx):
labels = [class2idx['outside']] * len(generated)
for ent in entities:
l = class2idx[ent['class_name']]
for span in re.finditer(ent['entity_name'].lower(), generated.lower()):
s, e = span.start(), span.end()
labels[s] = l
labels[s + 1:e] = [l + 1] * (e - s - 1)
return labels
class2idx = {e['class_name']: i * 2 for i, e in enumerate(all_entities)}
class2idx['outside'] = len(class2idx) * 2
data = []
for _ in tqdm(range(100)):
batch_data = []
for _ in range(10):
batch_entities = sample_entities(all_entities)
batch_prompt = construct_sentence_prompt(batch_entities)
generated_text = generate(batch_prompt)
labels = construct_labels(generated_text, batch_entities, class2idx)
batch_data.append({'text': generated_text, 'labels': labels})
data.extend(batch_data)
print(data)
LABELS = ['B-PERSON', 'I-PERSON', 'B-REGION', 'I-REGION', 'B-DATETIME', 'I-DATETIME', 'B-CORPORATION', 'I-CORPORATION', 'B-DISEASE', 'I-DISEASE', 'O']
def pad_sequences(seqs, pad_val, max_length):
_max_length = max([len(s) for s in seqs])
max_length = min(max_length, _max_length)
padded_seqs = []
for seq in seqs:
seq = seq[:max_length]
pads = [pad_val] * (max_length - len(seq))
seq = seq + pads
padded_seqs.append(seq)
return padded_seqs
class Dataset(torch.utils.data.Dataset):
def __init__(self, data, tokenizer, max_length, split='train'):
self.data = data
self.tokenizer = tokenizer
self.max_length = max_length
self.split = split
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
item = self.data[idx]
text = item['text']
char_labels = item['labels']
inputs = self.tokenizer(text)
input_ids = inputs.input_ids
attention_mask = inputs.attention_mask
labels = []
for i in range(len(input_ids)):
span = inputs.token_to_chars(i)
if span is None:
labels.append(len(LABELS) - 1) # O
else:
labels.append(char_labels[span.start])
return input_ids, attention_mask, labels
def collate_fn(self, batch):
input_ids, attention_mask, labels = zip(*batch)
input_ids = pad_sequences(input_ids, self.tokenizer.pad_token_id, self.max_length)
attention_mask = pad_sequences(attention_mask, 0, self.max_length)
labels = pad_sequences(labels, -100, self.max_length)
return torch.tensor(input_ids), torch.tensor(attention_mask), torch.tensor(labels)
tokenizer = AutoTokenizer.from_pretrained('roberta-base', clean_up_tokenization_spaces=True)
rand_idxs = np.random.permutation(range(len(data)))
train_idxs = rand_idxs[100:]
valid_idxs = rand_idxs[:100]
train_data = [data[i] for i in train_idxs]
valid_data = [data[i] for i in valid_idxs]
train_dataset = Dataset(train_data, tokenizer, 256)
train_loader = torch.utils.data.DataLoader(train_dataset, batch_size=16, shuffle=True, collate_fn=train_dataset.collate_fn)
valid_dataset = Dataset(valid_data, tokenizer, 256)
valid_loader = torch.utils.data.DataLoader(valid_dataset, batch_size=16, shuffle=False, collate_fn=valid_dataset.collate_fn)
def train(model, loader, device, outside_weight=0.9):
model.train()
label_weight = torch.ones(model.num_labels)
label_weight[-1] = outside_weight
label_weight = label_weight.to(device)
pbar = tqdm(loader)
for batch in pbar:
batch = [b.to(device) for b in batch]
input_ids, attention_mask, labels = batch
outputs = model(input_ids, attention_mask)
logits = outputs.logits
logits = logits.view(-1, model.num_labels)
labels = labels.view(-1)
loss = F.cross_entropy(logits, labels, weight=label_weight)
optimizer.zero_grad()
loss.backward()
optimizer.step()
pbar.set_postfix({'loss': loss.item()})
def predict(model, loader, device):
model.eval()
total_preds, total_labels = [], []
for batch in tqdm(loader):
batch = [b.to(device) for b in batch]
input_ids, attention_mask, labels = batch
with torch.no_grad():
outputs = model(input_ids, attention_mask, labels=labels)
preds = outputs.logits.argmax(dim=-1)
total_preds += preds.cpu().tolist()
total_labels += labels.cpu().tolist()
return total_preds, total_labels
def remove_padding(preds, labels):
removed_preds, removed_labels = [], []
for p, l in zip(preds, labels):
if -100 not in l: continue
idx = l.index(-100)
removed_preds.append(p[:idx])
removed_labels.append(l[:idx])
return removed_preds, removed_labels
def entity_f1_func(preds, targets):
preds = [[LABELS[p] for p in pred] for pred in preds]
targets = [[LABELS[t] for t in target] for target in targets]
entity_macro_f1 = ner_f1_score(targets, preds, average="macro", mode="strict", scheme=IOB2)
f1 = entity_macro_f1 * 100.0
return round(f1, 2)
def char_f1_func(preds, targets):
label_indices = list(range(len(LABELS)))
preds = list(itertools.chain(*preds))
targets = list(itertools.chain(*targets))
f1 = f1_score(targets, preds, labels=label_indices, average='macro', zero_division=True) * 100.0
return round(f1, 2)
def evaluate(model, loader, device):
preds, labels = predict(model, loader, device)
preds, labels = remove_padding(preds, labels)
entity_f1 = entity_f1_func(preds, labels)
char_f1 = char_f1_func(preds, labels)
return entity_f1, char_f1
num_labels = len(LABELS)
id2label = {i: l for i, l in enumerate(LABELS)}
label2id = {l: i for i, l in enumerate(LABELS)}
model = AutoModelForTokenClassification.from_pretrained('roberta-base', num_labels=num_labels, id2label=id2label, label2id=label2id)
_ = model.train().to('cpu')
optimizer = torch.optim.Adam(model.parameters(), lr=5e-5)
best_score = 0.
for ep in range(5):
train(model, train_loader, 'cpu')
entity_f1, char_f1 = evaluate(model, valid_loader, 'cpu')
print(f'단계: {ep:02d} | 엔터티 f1: {entity_f1:.2f} | 단어 f1: {char_f1:.2f}')
if entity_f1 > best_score:
model.save_pretrained('checkpoint')
tokenizer.save_pretrained('checkpoint')
best_score = entity_f1
import torch
from transformers import AutoTokenizer, AutoModelForTokenClassification
# 체크포인트 로드
checkpoint_path = 'checkpoint'
tokenizer = AutoTokenizer.from_pretrained(checkpoint_path)
model = AutoModelForTokenClassification.from_pretrained(checkpoint_path)
# 레이블 정의
LABELS = ['B-PERSON', 'I-PERSON', 'B-REGION', 'I-REGION', 'B-DATETIME',
'I-DATETIME', 'B-CORPORATION', 'I-CORPORATION',
'B-DISEASE', 'I-DISEASE', 'O']
def predict_ner(model, tokenizer, sentence):
# 토크나이징 (오프셋 정보 포함)
inputs = tokenizer(
sentence,
return_tensors="pt",
return_offsets_mapping=True,
return_special_tokens_mask=True,
add_special_tokens=True
)
# 워드 ID는 tokenizer의 word_ids 메소드로 별도 획득
word_ids = inputs.word_ids(0)
input_ids = inputs.input_ids
attention_mask = inputs.attention_mask
offsets = inputs.offset_mapping[0].numpy()
special_tokens_mask = inputs.special_tokens_mask[0].numpy()
# 예측 수행
with torch.no_grad():
outputs = model(input_ids, attention_mask=attention_mask)
predictions = torch.argmax(outputs.logits, dim=-1)[0].numpy()
# 엔티티 추출 및 병합
return extract_entities(sentence, offsets, predictions, word_ids, special_tokens_mask)
def extract_entities(sentence, offsets, predictions, word_ids, special_tokens_mask):
"""
원본 텍스트에서 엔티티 추출 및 같은 단어에 속한 토큰 병합
"""
entities = []
current_entity = None
prev_word_id = None
# 단어 ID별로 토큰 위치 및 예측 정보 수집
word_info = {}
for i, (offset, pred, word_id, is_special) in enumerate(
zip(offsets, predictions, word_ids, special_tokens_mask)):
# 특수 토큰 건너뛰기
if is_special:
continue
start, end = offset
label = LABELS[pred]
# 단어 ID별 정보 수집
if word_id not in word_info:
word_info[word_id] = {
'start': start,
'end': end,
'labels': [label]
}
else:
word_info[word_id]['end'] = end
word_info[word_id]['labels'].append(label)
# 단어별로 최종 레이블 결정
word_entities = []
for word_id, info in word_info.items():
start = info['start']
end = info['end']
text = sentence[start:end]
# 우선순위: B- > I- > O
label = 'O'
for l in info['labels']:
if l.startswith('B-'):
label = l
break
elif l.startswith('I-') and label == 'O':
label = l
if label != 'O':
entity_type = label[2:] # "B-" 또는 "I-" 제거
word_entities.append((word_id, entity_type, text, start, end))
# 연속된 같은 타입의 엔티티 병합
current_entity = None
merged_entities = []
for i, (word_id, entity_type, text, start, end) in enumerate(sorted(word_entities, key=lambda x: x[0])):
if current_entity is None:
current_entity = (entity_type, text, start, end)
elif current_entity[0] == entity_type and start <= current_entity[3] + 1:
# 같은 타입이고 가까운 위치에 있으면 병합
merged_text = sentence[current_entity[2]:end]
current_entity = (entity_type, merged_text, current_entity[2], end)
else:
merged_entities.append(current_entity)
current_entity = (entity_type, text, start, end)
if current_entity:
merged_entities.append(current_entity)
# 결과 형식 정리 (중복 제거)
result_dict = {}
for entity_type, text, start, end in merged_entities:
key = f"{start}_{end}_{entity_type}"
if key not in result_dict:
result_dict[key] = (entity_type, text)
return list(result_dict.values())
# 테스트 문장
sentence = "이순신 장군은 서울특별시에서 감기에 걸렸습니다."
entities = predict_ner(model, tokenizer, sentence)
# 결과 출력
print(f"Sentence: {sentence}")
print("Entities:")
for entity_type, entity_name in entities:
print(f" - {entity_name} ({entity_type})")
<분류 결과>
Sentence: 이순신 장군은 서울특별시에서 감기에 걸렸습니다.
Entities:
- 이순신 (PERSON)
- 서울특별시에서 (REGION)
- 감기에 (DISEASE)
Sentence: 1592년의 경상남도 거제현에서의 옥포해전은 이순신의 첫 승전을 알리게 된 해전이다.
Entities:
- 1592년의 (DATETIME)
- 이순신의 (PERSON)
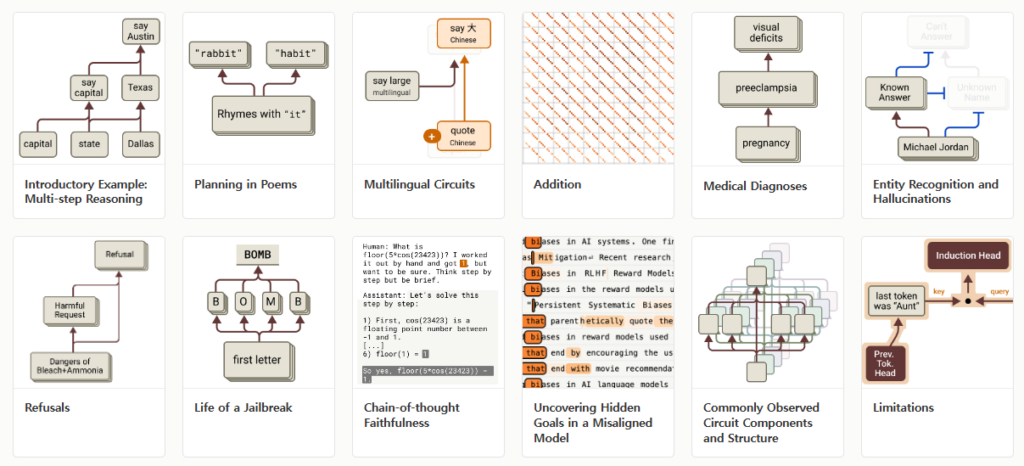
이 기사는 앤트로픽이 대형언어모델(LLM)의 내부 작동 방식을 분석하는 기술을 개발하여 ‘클로드’의 작업 수행 과정을 통해 몇 가지 새로운 특징을 발견했다는 내용을 다루고 있습니다.
앤트로픽은 LLM이 작업을 수행할 때 활성화되는 경로를 분석하는 ‘회로 추적’ 기술을 개발했습니다.
LLM이 답을 생성하기 전에 미리 계획하고, 여러 단계를 거친 논리적 추론을 수행하며, 응답을 생성하기 전 ‘개념’을 추상적 표현으로 변환한다는 사실을 밝혀냈습니다.
LLM이 헛소리를 출력하는 과정과 환각을 일으키는 이유도 분석했습니다.
이 연구는 LLM의 안전 문제를 효과적으로 점검하고 조정할 수 있는 가능성을 열어준다고 설명합니다.
사람의 신체에서 가장 복잡한 뇌 연구가 끝판왕이라 생각되는데, 이제 인공지능의 뇌도 열어볼 정도로 기술이 나날이 발전하고 있네요…
LLM의 내부 작동 방식에 대한 이해가 깊어짐에 따라, LLM의 안전성과 신뢰성을 향상시킬 수 있을 것으로 예상되며, LLM이 인간의 사고 과정을 모방하는 능력이 더욱 발전하여, 보다 정교하고 복잡한 작업을 수행할 수 있게 될 것으로 기대되네요.
“타이핑 없이 느낌으로 코딩하는 시대…’바이브코딩’오나”
이 기사는 AI를 활용한 소프트웨어 개발 방식인 ‘바이브 코딩‘에 대해 논의합니다. AI 기술의 발전으로 소프트웨어 개발 방식이 크게 변화하고 있으며, 오픈AI의 공동 창립자인 안드레이 카파시는 자연어와 음성 명령을 통해 AI에 코드 작성을 지시하는 ‘바이브 코딩’ 개념을 소개했습니다.
AI 도구는 UI 변경, 버그 수정, 코드 검토 등의 작업을 수행할 수 있으며, 이를 통해 생산성 향상과 비개발자도 애플리케이션을 만들 수 있는 기회를 제공합니다.
하지만 코드 품질, 보안 취약점, AI 생성 코드의 장기적인 유지 보수 문제 등 우려도 있습니다. 그럼에도 불구하고 Google, Microsoft, Amazon 등 주요 기술 기업들이 AI 기반 개발 도구를 개발하고 있어, AI 지원 개발이 주요 트렌드가 되고 있습니다.
AI가 생활이 침투하는 속도가 정말 빠르네요…..
미래에는 AI가 소프트웨어 개발에서 더욱 중요한 역할을 할 것으로 예상됩니다. AI가 인간 개발자를 완전히 대체하지는 않겠지만, 개발자의 역할을 바꿀 것입니다.
AI를 효과적으로 사용하고, 명확한 지침을 제공하며, 비즈니스 요구와 기술적 솔루션을 결합하는 능력이 중요한 기술이 될 것입니다.
AI 생성 코드의 품질과 유지 보수에 대한 우려가 있지만, AI 기술의 발전으로 점차 더 안정적이고 능력 있는 AI가 될 것으로 예상됩니다. 이는 개발 주기 단축, 비용 절감, 비기술 사용자의 소프트웨어 개발 참여 확대 등으로 이어질 수 있습니다.
“엔비디아, 트랜스포머의 순차 계산 문제 해결하는 ‘FFN 퓨전’ 아키텍처 공개”
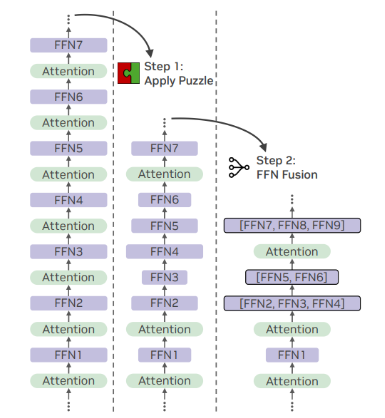
엔비디아는 대형언어모델(LLM)의 순차적 계산 문제를 해결하기 위해 ‘FFN 퓨전’ 아키텍처를 개발했습니다. FFN 퓨전은 트랜스포머 모델의 피드 포워드 네트워크(FFN)의 순차적 처리로 인해 발생하는 비효율성을 개선하기 위해 고안되었습니다.
이 기술은 여러 연속적인 FFN 레이어를 하나의 더 넓은 FFN으로 결합하여 병렬 처리를 가능하게 함으로써 계산 시간을 줄이고 성능을 향상시킵니다. 엔비디아 연구진은 ‘라마-3.1-405B-인스트럭트’ 모델에 FFN 퓨전을 적용하여 성능과 효율성을 크게 향상한 ‘울트라-253B-베이스‘를 개발했습니다.
테스트 결과, 울트라-253B-베이스는 추론 지연 시간을 1.71배 향상시키고, 배치 크기 32에서 토큰당 계산 비용을 35배 절감하는 성과를 보였습니다. 또한, 다양한 벤치마크에서 ‘라마-3.1-405B-인스트럭트’와 비슷하거나 능가하는 성능을 나타냈으며, 메모리 사용량도 2배 절감되었습니다.
FFN 퓨전은 더 큰 모델에서 더 효과적이며, 양자화 및 가지치기와 같은 기존 최적화 기술을 보완할 수 있습니다. 엔비디아는 어텐션과 FFN 레이어를 모두 포함하는 전체 변압기 블록조차도 병렬화될 수 있음을 확인하여 신경 구조 설계에 대한 새로운 방향을 제시했습니다.
FFN 퓨전이 대형언어모델의 성능과 효율성을 크게 향상시킬 수 있는 잠재력을 보여주었네요. 큰 대형 모델에서 더 효과적이며, 양자화 및 가지치기와 같은 기존 최적화 기술을 보완하여, 향후 더욱 효율적인 대형언어모델의 개발로 이어질 것으로 기대되네요.
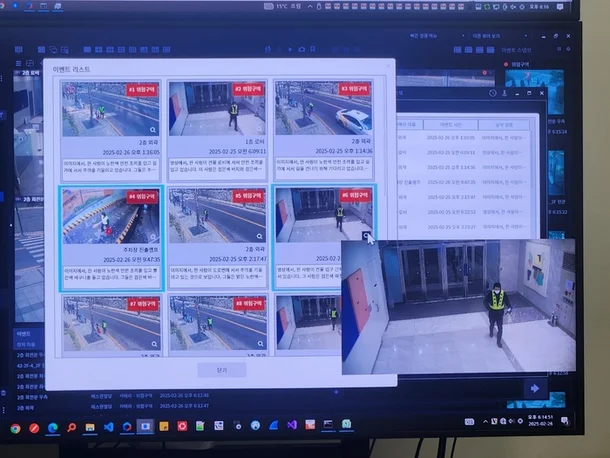
“‘눈빠지게 안봐도 된다’…인공지능 단 CCTV, 감시 넘어 판단까지”
에스원이 개발한 SVMS CCTV는 인공지능(AI) 에이전트 기술을 탑재하여 음성 검색으로 영상 검색이 가능한 스마트 비디오 매니지먼트 시스템입니다. 이 시스템은 거대언어모델(LLM) 기반의 대화형 영상관제 기술과 영상 언어모델을 융합하여 실시간 및 과거 영상 검색, 데이터 변환, 이상행동 분석, 표준 운영 절차 제공 등 다양한 기능을 수행합니다. 이를 통해 보안 인력의 업무 효율성을 높이고, 실시간 감시 및 대응 능력을 향상시킬 수 있다고 합니다.
에스원의 SVMS CCTV 개발은 단순 감시를 넘어 상황 판단 및 대응까지 가능한 AI 기반 CCTV 시스템의 미래를 보여주네요. 이러한 기술 발전은 “개인정보 보호 및 윤리적 문제”에 큰 변화를 가져올 것으로 예상되네요.
“중국, 자율주행 무인 드론 첫 인증… ‘저고도 경제’ 서막 올랐다“
중국 당국이 승객 수송용 자율주행 무인기(드론)에 첫 운항 인증서를 발급했습니다. 인증을 받은 드론은 ‘EH216-S’로, 무인 전기 수직 이착륙기(eVTOL)이며, 이항 홀딩스와 허페이 허이 항공이 공동 개발했습니다.
이 드론은 도시 항공 이동, 물류, 관광 등 다양한 분야에서 활용될 것으로 예상됩니다. 중국은 ‘저고도 경제’ 규모가 200조 원에 달할 것으로 전망하며, 관련 산업 육성에 적극적으로 나서고 있습니다. 향후 2~3년 내에 중국 주요 도시에서 드론 택시와 같은 저고도 경제 활동이 본격화될 것으로 예상됩니다.
중국이 자율주행 드론 택시를 상용화함으로써 저고도 경제를 선도하려는 움직임을 보이고 있네요. 이는 단순한 교통수단을 넘어, 물류, 관광 등 다양한 산업 분야에 혁신을 가져올 잠재력을 지니고 있습니다.
중국 정부의 적극적인 지원과 기술 개발을 통해 저고도 경제가 빠르게 성장할 것으로 예상됩니다. 저고도 경제의 성장은 새로운 산업 생태계와 일자리 창출에 기여할 수 있습니다.
최근 몇 년간 대규모 언어 모델(LLM, Large Language Model)은 자연어 처리(NLP) 분야에서 혁신적인 변화를 이끌어왔습니다. ChatGPT, Bard, Claude와 같은 상용 LLM은 놀라운 성능을 제공하지만, 대부분의 경우 사용자는 높은 비용을 지불해야 합니다. 이러한 비용 문제는 특히 스타트업, 개인 개발자, 소규모 연구팀에게 부담으로 작용할 수 있습니다.
이에 따라 무료 또는 최소한의 비용으로 LLM을 개발하거나 활용하려는 움직임이 점점 더 주목받고 있습니다. 오픈소스 모델을 활용하여 LLM을 개발하는 방법과 그 이점, 그리고 이를 통해 얻을 수 있는 가능성에 대해 깊이 탐구해보고자 합니다.
왜 무료 또는 저비용 LLM 개발이 필요한가?
1. 비용 절감
상용 LLM은 API 호출당 비용이 발생하며, 대규모 데이터 처리나 반복적인 작업이 필요한 경우 비용이 기하급수적으로 증가합니다. 예를 들어, 한 달 동안 수백만 번의 API 호출을 하는 애플리케이션은 수천 달러 이상의 비용이 들 수 있습니다. 반면 오픈소스 모델은 초기 설정 비용만 발생하며, 이후에는 클라우드 또는 로컬 서버에서 실행하여 지속적인 비용을 줄일 수 있습니다.
2. 커스터마이징 가능
상용 모델은 제한된 커스터마이징 옵션을 제공하며, 특정 도메인에 맞춘 튜닝이 어려울 수 있습니다. 반면 오픈소스 모델은 코드와 가중치가 공개되어 있어 특정 산업이나 애플리케이션에 맞게 조정할 수 있습니다.
3. 데이터 프라이버시
상용 LLM을 사용할 경우 데이터가 외부 서버로 전송되며, 이는 민감한 정보를 다루는 프로젝트에서 보안 리스크를 초래할 수 있습니다. 오픈소스 모델은 로컬 환경에서 실행 가능하므로 데이터 프라이버시를 보장할 수 있습니다.
무료 또는 저비용 LLM 개발의 주요 접근 방식
1. 오픈소스 모델 활용
오픈소스 커뮤니티는 대규모 언어 모델의 발전에 크게 기여하고 있습니다. Hugging Face와 같은 플랫폼에서는 다양한 사전 학습된 모델을 제공하며, 이를 기반으로 새로운 애플리케이션을 구축할 수 있습니다.
대표적인 오픈소스 LLM
GPT-NeoX: EleutherAI에서 개발한 GPT 계열의 오픈소스 모델로, 성능과 확장성이 뛰어납니다.
LLaMA: Meta에서 공개한 모델로, 높은 성능과 효율성을 자랑합니다.
Bloom: BigScience 프로젝트에서 개발한 다국어 지원 오픈소스 모델로, 다양한 언어와 도메인에 적합합니다.
Falcon: TII(Tecnhology Innovation Institute)에서 공개한 고성능 언어 모델로, 상업적 사용도 허용됩니다.
2. 효율적인 학습 및 튜닝
대규모 언어 모델을 처음부터 학습시키는 것은 막대한 리소스를 요구하지만, 아래 방법들을 통해 이를 줄일 수 있습니다.
사전 학습된 모델 활용: 기존에 학습된 가중치를 기반으로 파인튜닝만 수행하면 훨씬 적은 데이터와 리소스로 원하는 성능을 얻을 수 있습니다.
LoRA (Low-Rank Adaptation): 파인튜닝 과정에서 메모리 사용량과 계산량을 줄이는 기술로, 많은 연구팀이 채택하고 있습니다.
양자화(Quantization): 모델 크기를 줄이고 실행 속도를 높이는 기술로, 로컬 환경에서도 대규모 모델 실행이 가능하도록 돕습니다.
무료 또는 저비용 개발의 장점
1. 혁신적인 아이디어 실현
무료 또는 저비용으로 LLM을 활용하면 누구나 실험적이고 창의적인 아이디어를 실현할 기회를 얻습니다. 이는 스타트업이나 개인 개발자가 새로운 서비스를 개발하는 데 큰 도움이 됩니다.
2. 커뮤니티 협력 강화
오픈소스 프로젝트는 커뮤니티 협력을 통해 발전합니다. 전 세계의 연구자와 개발자가 함께 문제를 해결하고 개선점을 찾으므로 빠른 발전이 가능합니다.
3. 교육 및 연구 활성화
대학이나 연구기관에서는 예산 제한으로 인해 상용 LLM 사용이 어려운 경우가 많습니다. 오픈소스 모델은 교육 및 연구 목적으로 자유롭게 사용할 수 있어 학문적 발전에 기여합니다.
무료 또는 저비용 개발의 도전 과제
물론 무료 또는 저비용으로 LLM을 개발하는 데도 몇 가지 도전 과제가 존재합니다.
1. 하드웨어 제한
대규모 언어 모델은 GPU 메모리와 연산 능력이 요구됩니다. 개인이나 소규모 팀은 이러한 하드웨어를 갖추기가 어려울 수 있습니다.
2. 기술적 난이도
오픈소스 모델은 상용 API처럼 간단히 사용할 수 있는 인터페이스를 제공하지 않는 경우가 많습니다. 따라서 설치와 운영 과정에서 기술적 난관에 직면할 가능성이 큽니다.
3. 성능 격차
상업적 LLM은 최첨단 기술과 방대한 데이터로 훈련되어 있어 특정 작업에서 더 나은 성능을 발휘할 수 있습니다. 오픈소스 모델은 일부 작업에서 성능 격차가 존재할 수 있습니다.
결론: 지속 가능한 AI 개발의 방향
무료 또는 최소 비용으로 LLM을 개발하려는 노력은 AI 기술의 민주화를 위한 중요한 움직임입니다. 이는 모든 사람이 AI 기술에 접근하여 자신의 아이디어를 실현하고 혁신적인 솔루션을 만들 기회를 제공합니다.
오픈소스 LLM 생태계는 빠르게 성장하고 있으며, 이를 통해 더 많은 사람들이 상업적 제약 없이 AI 기술을 활용할 수 있게 되었습니다. 앞으로도 이러한 흐름은 지속될 것이며, 많은 개발자와 연구자가 참여하여 AI 기술의 발전과 보급에 기여하길 기대합니다.