아이언우드는 추론을 위해 설계되었으며 이전 TPU보다 더 강력하고 에너지 효율적입니다. 최대 9,216개의 칩으로 확장 가능하며 42.5 Exaflops의 컴퓨팅 성능을 제공합니다. 이는 대규모 언어 모델 및 혼합 전문가와 같은 “사고 모델”의 계산 요구 사항을 처리하도록 구축되었습니다.
아이언우드는 향상된 SparseCore, 증가된 HBM 용량 및 대역폭, 개선된 ICI 네트워킹이 특징입니다. 구글 클라우드 고객은 고성능 및 효율성으로 까다로운 AI 워크로드를 처리할 수 있습니다. Gemini 2.5 및 노벨상 수상자인 AlphaFold와 같은 주요 사고 모델은 모두 오늘날 TPU에서 실행됩니다. 아이언우드는 올해 말 구글 클라우드 고객에게 제공될 예정입니다.
참고)
특징
아이언우드 TPU (최대 구성)
NVIDIA H200 (단일 GPU)
NVIDIA B200 (단일 GPU, 추정)
주요 목표
추론
범용 (학습 및 추론)
범용 (학습 및 추론)
FP8 성능
42.5 Exaflops
2 Petaflops (추정)
4.5 Petaflops (추정)
HBM 용량
9,216 칩 구성 시 총 192GB/칩
141GB
192GB
HBM 대역폭
7.2 TB/s/칩
4.8 TB/s
최대 8 TB/s
상호 연결 대역폭
1.2 TB/s (양방향, 칩 간)
900 GB/s (NVLink)
–
전력 효율
이전 대비 2배 향상
–
–
아이언우드는 추론에 특화 설계되었으며, NVIDIA 칩들은 범용적인 워크로드에 맞춰져 있습니다. 따라서 직접적인 성능 비교는 어려울 수 있습니다. 표의 NVIDIA GB200 수치는 NVL72 구성(72개 GPU) 기준이며, B200은 단일 칩 기준입니다. FP8 성능은 측정 방식과 조건에 따라 차이가 있을 수 있습니다. NVIDIA 칩의 경우, 스파시티(sparsity)를 활용한 성능 수치를 별도로 제시하는 경우가 많으나, 여기서는 일반적인 FP8 성능을 기준으로 비교했습니다. 아이언우드는 칩 간 상호 연결 대역폭이 높은 것이 특징이며, 이는 대규모 추론 작업에 유리할 수 있습니다. 구글은 아이언우드의 전력 효율이 이전 세대 대비 2배 향상되었다고 강조합니다.
구글은 검색, 지메일, 유튜브, AI에 반도체 칩까지…. 모든 분야에서 선도적인 기업이라고 생각되네요….
아이언우드는 AI 추론 분야에서 중요한 발전을 의미합니다. 성능과 에너지 효율성이 향상되어 더 복잡한 AI 모델을 더 효율적으로 실행할 수 있습니다. 이는 AI 기술의 발전을 가속화하고 다양한 산업에 혁신을 가져올 수 있습니다. 아이언우드가 구글 클라우드 고객에게 제공되면 AI 채택이 더욱 확대될 것으로 예상됩니다.
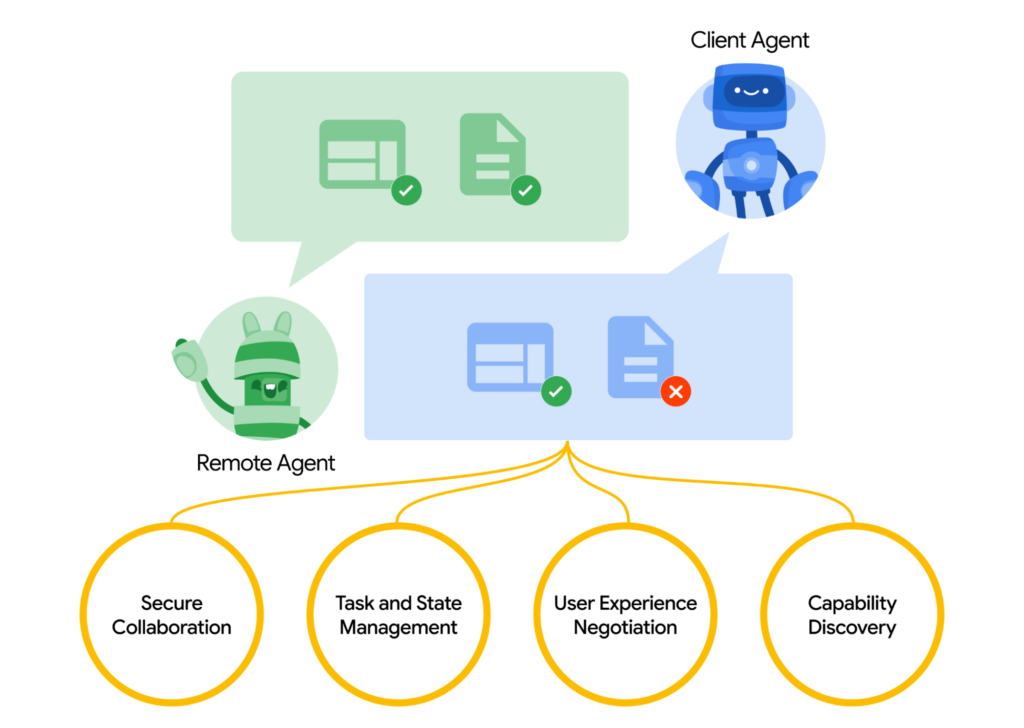
구글이 AI 에이전트들이 서로 안전하게 정보를 교환하고 작업을 조율할 수 있도록 돕는 새로운 오픈 프로토콜, Agent2Agent (A2A)를 발표했습니다. A2A 프로토콜은 다양한 플랫폼과 애플리케이션에서 AI 에이전트 간의 상호 운용성을 높여, 기업들이 AI 에이전트를 통해 업무 효율성을 극대화하고 비용을 절감할 수 있도록 설계되었습니다.
A2A 프로토콜은 에이전트가 서로 다른 벤더나 프레임워크에서 구축되었더라도 원활하게 협업할 수 있도록 지원합니다. 이 프로토콜은 HTTP, SSE, JSON-RPC와 같은 기존의 인기 있는 표준을 기반으로 구축되어 기존 IT 스택과의 통합이 용이하며, 엔터프라이즈급 인증 및 권한 부여 기능을 기본적으로 제공하여 보안을 강화했습니다. 또한, A2A는 빠른 작업부터 오랜 시간이 걸리는 작업까지 다양한 시나리오를 지원하며, 텍스트뿐만 아니라 오디오 및 비디오 스트리밍과 같은 다양한 형식을 처리할 수 있도록 설계되었습니다.
A2A 프로토콜을 통해 클라이언트 에이전트는 “Agent Card”를 사용하여 작업 수행에 가장 적합한 에이전트를 식별하고, 작업을 요청할 수 있습니다. 에이전트 간의 통신은 작업 완료를 중심으로 이루어지며, 작업의 결과물은 “아티팩트”로 정의됩니다. 에이전트들은 메시지를 통해 컨텍스트, 응답, 아티팩트 또는 사용자 지침을 주고받을 수 있으며, 각 메시지는 콘텐츠 유형을 지정하여 클라이언트와 원격 에이전트 간의 형식 협상을 가능하게 합니다.
“구글은 A2A 프로토콜이 AI 에이전트 생태계의 혁신을 촉진하고, 더욱 강력하고 다재다능한 에이전트 시스템을 구축하는 데 기여할 것으로 기대하고 있습니다. 구글은 파트너 및 커뮤니티와의 협력을 통해 프로토콜을 지속적으로 개발하고 있으며, 오픈 소스로 공개하여 누구나 기여할 수 있도록 했습니다.”
인공지능(AI)이 의료 진단 분야에서 인간 의사를 능가하는 능력을 보여주고 있다는 내용입니다. 오픈AI의 최신 AI 모델인 GPT-4는 임상 사례를 기반으로 한 진단 테스트에서 인간 의사보다 16%포인트 더 높은 정확도를 기록했습니다. 스탠퍼드대학교 인간중심인공지능연구소(HAI)의 ‘AI 인덱스 2025’ 보고서에 따르면, GPT-4는 단독 진단 성능이 가장 높았으며, 인간 의사와 협업할 경우에도 활용 방식에 따라 성과 편차가 컸습니다. AI는 로봇 수술, 의학 데이터 분석, 암 검진 솔루션 등 다양한 의료 분야에 도입되고 있으며, GPT-4는 ‘메드QA’ 벤치마크 테스트에서도 높은 정확도를 기록했습니다. 보고서는 AI와 의사의 협업이 최선의 결과를 낳을 수 있다고 언급하면서도, AI 시스템의 신뢰성과 안전성에 대한 우려를 제기했습니다.
AI 기술의 발전으로 의료 분야에서 AI의 역할이 확대될 가능성이 높으며, AI 의사의 시대가 가까워지고 있다는 것입니다. AI는 의료 서비스의 질을 개선하고, 의료진의 업무 효율성을 높이는 데 기여할 수 있습니다. AI 시스템의 신뢰성과 안전성에 대한 우려를 해소하고, 정책적 대비가 필요해 보입니다.
[AI는 지금] “양보다 질이다”…AI 기업들, 정제 데이터 ‘버티컬 모델’ 베팅
AI 산업이 일반적인 대규모 언어 모델(LLM)에서 특정 산업에 맞는 ‘버티컬 AI’ 모델로 전환되고 있음을 논의합니다.
일반 LLM은 다양한 주제를 빠르게 학습할 수 있다는 장점이 있지만, 특정 산업에 필요한 정확도, 상황 이해, 규제 준수가 부족한 경우가 많습니다. 법률, 금융, 상거래 등 특정 산업에 맞게 설계된 수직형 AI는 강화된 문제 해결 능력, 데이터 기반 경량화 전략, 향상된 정확도로 인해 인기를 얻고 있습니다.
BHSN의 ‘앨리비’ 법률 문서 분석, ‘젠투’ 전자 상거래 고객 참여, ‘알프’ 패션 및 뷰티 산업 고객 서비스 등 수직형 AI 응용 프로그램의 여러 예가 있습니다.
이러한 애플리케이션은 다양한 산업에서 효율성을 높이고 오류를 줄이며 고객 만족도를 향상시킬 수 있는 수직형 AI의 잠재력을 보여줍니다. 기사는 AI 기술의 미래가 특정 산업에 맞게 최적화된 방식으로 작동하는 능력에 달려 있으며, 이러한 특화가 기술 경쟁력의 핵심 요소가 될 것임을 시사합니다.
수직형 AI는 특정 산업에 맞게 설계되어 일반 LLM보다 더욱 정확하고 효율적이며, 다양한 산업에서 활용되어 비용 절감과 생산성 향상에 기여할 수 있습니다. AI 기술의 발전과 상용화를 가속화할 것으로 예상됩니다.
AI 총동원해 오즈의마법사 생성…구글이 보여준 동영상 AI의 미래 [팩플]
구글은 1939년 작은 셀룰로이드 필름 프레임으로 찍힌 영화를 스피어의 초대형 고해상도(16K) LED 스크린에 맞출 수 있게끔 이미지를 바꿔주는 AI 기반 도구를 개발했다. 전통적인 영화 프레임보다 훨씬 넓은 스피어의 초대형 화면을 실감나게 채우기 위해 기존 영화 프레임 바깥에 있던 이미지도 동영상 AI 기술(AI 아웃페인팅)로 생성해 냈다. 실제로 스피어 화면에 펼쳐진 도로시와 양철 나무꾼 영상은 최신 영화라고 해도 믿을만큼 선명했고, 이질감도 없었다.
이 프로젝트에는 Google Cloud, Google DeepMind, Sphere Studios, Warner Bros.가 협력했으며 영화 및 기술 산업에서 수천 명이 참여했습니다. Google은 AI 기반 도구를 개발하여 영화 이미지를 스피어의 16K 해상도 화면에 맞게 조정하고 AI 아웃페인팅 기술을 사용하여 원래 영화 프레임 외부의 새로운 이미지를 생성했습니다.
Google은 영화 산업에서 AI와 인간 창작자 간의 협력 모델을 구축하는 것을 목표로 합니다. ‘오즈의 마법사’의 향상된 버전은 8월 28일 스피어에서 개봉될 예정입니다.
사람처럼 사고하는 AI 시대…구글도 추론용 AI칩 내놨다
Google이 라스베이거스에서 열린 Next 2025 기술 컨퍼런스에서 첫 번째 추론 전용 AI 칩인 Ironwood를 소개한 것에 대해 논의합니다. 이 칩의 개발은 AI 업계가 단계별 문제 해결을 제공하여 인간과 유사한 사고를 모방하는 추론 모델로 이동하는 것을 의미합니다. 이는 학습된 패턴에서 확률에 따라 답변을 생성하는 기존 AI 모델과는 대조적입니다.
Ironwood TPU는 Google의 첫 번째 TPU에 비해 3600배의 성능 향상을 자랑하여 AI 에이전트가 요구하는 복잡한 작업을 처리할 수 있습니다. Google은 또한 간단한 질문에 빠른 답변과 복잡한 질문에 대한 더 자세한 답변을 제공하도록 설계된 경량화된 추론 AI 모델인 Gemini 2.5 Flash를 공개했습니다. 이 기사는 AI 랜드스케이프에서 추론 모델의 중요성이 커지고 이러한 모델을 지원하기 위한 강력한 컴퓨팅 성능에 대한 수요가 증가함에 따라 Google의 노력을 강조합니다.
AI 모델 편향·환각 줄이는 ‘머신 언러닝 플랫폼’…LLM 공정성 강화
머신 러닝 스타트업 히룬도(Hirundo)가 AI 모델의 원치 않는 데이터나 동작을 관리하는 ‘머신 언러닝 플랫폼’을 발표했습니다. 이 플랫폼을 통해 메타의 라마 4 모델의 편향을 평균 44% 줄이는 데 성공했습니다.
머신 언러닝은 AI 모델에서 특정 지식을 제거하는 기술로, 히룬도는 이를 통해 편향 완화뿐 아니라 환각, 적대적 취약성, 유해한 출력 등의 문제도 해결할 수 있다고 합니다. 히룬도의 CEO 벤 루리아는 라마 4와의 협력을 통해 플랫폼의 견고성과 확장성을 입증했으며, 더 안전하고 공정한 AI 솔루션 배포를 지원하겠다고 밝혔습니다.
히룬도의 머신언러닝 플랫폼은 메타의 라마 4 모델에서 효과를 입증했으며, 앞으로 더욱 안전하고 공정한 AI 솔루션 개발에 기여할 것으로 기대됩니다.
추론형 AI 급성장…테스트 시장도 커진다
기사 요약
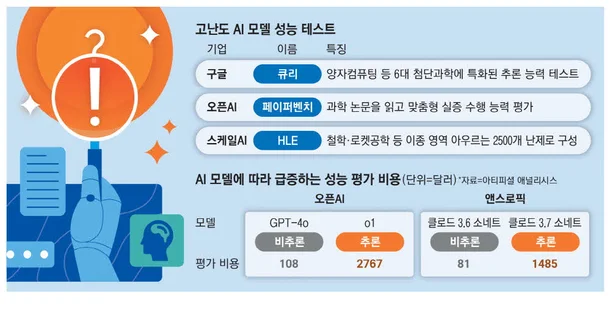
최근 인공지능(AI) 모델들의 성능을 객관적으로 평가하기 위한 고난도 벤치마크들이 등장하고 있습니다. 구글은 과학 분야 문제 해결 능력을 평가하는 ‘큐리’를, 오픈AI는 AI 에이전트의 연구 능력을 측정하는 ‘페이퍼벤치’를, 스케일AI는 100개 이상의 이종 영역에서 난제를 선별한 ‘HLE’를 개발했습니다.
그러나 일부 기업들이 자사 AI 모델의 성능을 과장하기 위해 벤치마크 결과를 조작하거나 유리한 지표만 선별해 공개하는 등 논란이 발생하고 있습니다. 또한, 추론 능력을 강조한 모델들의 등장으로 평가 비용이 급증하면서 독립적인 성능 검증이 어려워질 수 있다는 우려도 제기되고 있습니다.
– AI 성능 평가의 중요성 증대: AI 모델이 복잡한 추론 능력을 갖추게 되면서, 그 성능을 객관적으로 평가하는 벤치마크의 중요성이 더욱 커지고 있습니다. – 벤치마크의 진화: 기존 벤치마크의 한계를 극복하고 AI 모델의 실제 능력을 보다 정확하게 측정하기 위한 고난도 벤치마크들이 등장하고 있습니다. – 벤치마크 조작 및 신뢰성 문제: 일부 기업들의 벤치마크 결과 조작 및 과장 홍보는 AI 성능 평가의 신뢰성을 저해하고 있습니다. – 평가 비용 증가: 추론 능력을 강조한 모델들의 등장으로 평가 비용이 급증하면서, 독립적인 성능 검증이 어려워질 수 있다는 우려가 있습니다. – 통일된 평가 기준의 필요성: 다양한 AI 모델의 성능을 객관적으로 비교하기 위한 통일된 평가 기준 마련이 필요합니다.
영어 발음 교정까지 해주는 AI 교과서… 맞춤형 문제도 추천
AI 교과서는 학생들의 학업 성취도를 즉시 파악하고 맞춤형 문제를 추천하는 기능을 제공하여 교사들이 학생 개개인에게 더욱 효과적인 지도를 할 수 있도록 돕고 있습니다. 특히 영어 수업에서는 AI가 학생들의 발음을 교정해주는 기능이 유용하게 활용되고 있습니다.
AI 교과서 도입 초기에는 학부모들의 우려도 있었지만, 실제 사용 후에는 긍정적인 반응이 많았으며, 학생들도 AI 교과서의 다양한 문제 유형과 다른 학생들의 풀이 과정을 볼 수 있다는 점에 만족하고 있습니다. 다만, 일부 학생들은 기기 사용에 미숙한 모습을 보이기도 했습니다.
두차례나 ‘GPT-4.5’ 사전 훈련한 오픈AI…“GPT-4쯤은 5명으로 개발 가능”
오픈AI가 ‘GPT-4.5’ 개발 경험을 바탕으로 ‘GPT-4’ 수준의 모델을 더 적은 인원으로 개발할 수 있게 되었다는 내용을 다룹니다.
오픈AI는 ‘GPT-4.5’ 개발을 통해 얻은 기술적 노하우를 바탕으로, 과거 수백 명이 필요했던 ‘GPT-4’ 사전 훈련을 이제 5명으로 수행할 수 있게 되었다고 밝혔습니다.
샘 알트먼 CEO는 GPT-4.5 개발을 주도한 엔지니어들과의 팟캐스트에서 이 내용을 공유하며, GPT-4.5 사전 훈련 과정이 어려웠음을 시사했습니다.
오픈AI 연구원들은 모델 구축 경험이 반복 작업의 효율성을 크게 높여준다고 언급하며, 이를 “치트 키”에 비유했습니다.
GPT-4.5는 2월에 공개된 최신 모델로, 오픈AI는 이를 “가장 크고 강력한 모델”이라고 소개했지만, 개발 과정에서 성능 향상에 어려움을 겪어 사전 훈련을 다시 시작하기도 했습니다.
AI 스케일링 법칙에 대한 의문이 제기되었는데, 이는 더 많은 데이터와 컴퓨팅 자원을 투입하는 것만으로는 더 이상 큰 성능 향상을 기대하기 어렵다는 의미입니다.
알트먼 CEO는 GPT-4.5가 오픈AI의 마지막 비추론 모델이며, 앞으로는 플래그십 모델에 추론을 통합할 것이라고 예고했습니다.
오픈AI가 GPT-4.5 개발을 통해 모델 개발 효율성을 크게 높였다는 것을 보여줍니다. 이는 AI 모델 개발 비용을 낮추고, 더 많은 사람들이 AI 기술을 활용할 수 있도록 하는 데 기여할 것으로 기대됩니다. 또한, AI 스케일링 법칙에 대한 의문을 제기하며, AI 모델 개발이 더 이상 단순히 데이터와 컴퓨팅 자원을 투입하는 것만으로는 이루어지지 않을 수 있다는 점을 보여줍니다.
소향이 편곡한 곡들을 듣다 보면, 감정의 스펙트럼이 한순간에 폭발하는 듯한 경험을 하게 됩니다. 흥겨움과 감동이 교차하며, 마치 단 몇 분 만에 최고급 공연을 관람한 듯한 황홀함을 선사 받습니다. 그녀의 음악은 단순히 듣는 것을 넘어, 온몸으로 느끼게 만듭니다.
좋은 음악이 주는 감동은 누구에게나 비슷하게 다가오는 것 같습니다. 오늘 내가 느낀 것은 소향은 잘 알려진 멜로디에서는 눈물을 자아내고, 그녀만의 독창적인 편곡에서는 즐거움을 느끼게 한다는 점입니다. 이처럼 눈물과 흥분의 반복은 노래의 처음부터 끝까지 계속해서 전율을 일으킵니다.
소향의 가장 큰 강점은 그녀의 타고난 발성과 이를 활용한 표현력입니다. 그녀는 단순히 한 가지 감정에 머무르지 않고, 곡 안에 다양한 감정을 녹여내며 듣는 이들에게 생생하게 전달합니다. 특히, 감정의 강약을 섬세하게 조절하며 그 에너지와 진심을 고스란히 전하는 능력은 정말 대단합니다.
중앙 저장소: Amazon S3는 확장성, 내구성, 비용 효율성으로 인해 데이터 레이크의 중앙 저장소로 자주 사용됩니다.
데이터 수집: Kinesis와 같은 도구를 사용하여 실시간 스트리밍, 또는 Segment와 같은 플랫폼을 통해 데이터 수집.
처리 및 변환: Amazon EMR, AWS Glue, 또는 Upsolver와 같은 도구로 ETL 수행, 종종 Parquet와 같은 최적화된 형식으로 저장.
쿼리 및 분석: Amazon Athena 또는 Redshift Spectrum으로 S3에서 직접 쿼리, 또는 Amazon Redshift로 로드하여 복잡한 쿼리 수행.
시각화 및 BI: Power BI, Sisense 소프트웨어 등으로 보고서 및 시각화 생성.
실시간 처리: 실시간 분석이 필요한 경우 Kinesis, Lambda와 같은 서비스 통합.
비용 최적화: 장기 보관 데이터는 S3 Glacier로 저장하여 비용 절감.
AWS는 데이터 수집, 통합, 표준화, 분석을 위한 유연한 서비스 세트를 제공하며, 기업은 데이터 볼륨, 실시간 처리 필요성, 분석 복잡성, 비용 고려 사항에 따라 맞춤형 데이터 레이크 아키텍처를 구축할 수 있습니다. 위 사례들은 다양한 산업에서 AWS를 어떻게 활용하는지 보여주며, S3를 중심으로 한 설계가 표준화된 접근법임을 확인할 수 있습니다.
“Example Selector”는 주로 프롬프트 엔지니어링에서 few-shot 학습을 최적화하기 위해 사용되는 도구입니다.
LangChain을 활용해 대규모 언어 모델(LLM)을 다룰 때, 모델이 특정 작업을 수행하도록 유도하려면 적절한 프롬프트 설계가 필수적입니다. 특히 few-shot 학습(few-shot learning)에서는 모델에 제공되는 예시(example)가 결과의 품질에 큰 영향을 미칩니다. 그러나 모든 상황에서 고정된 예시를 사용하는 것은 비효율적일 수 있습니다. 작업의 맥락이나 입력 데이터에 따라 적합한 예시가 달라질 수 있기 때문입니다. 이 문제를 해결하기 위해 LangChain은 Example Selector라는 강력한 도구를 제공합니다.
Example Selector는 입력된 쿼리나 작업에 따라 동적으로 적합한 예시를 선택해 프롬프트에 포함시키는 도구입니다. LangChain에서 few-shot 학습을 구현할 때, 모든 예시를 나열하는 대신, 주어진 상황에 가장 관련성 높은 예시를 자동으로 골라내어 모델의 성능을 최적화합니다. 이는 특히 데이터셋이 크거나 예시의 다양성이 중요한 경우에 유용합니다.
예를 들어, 고객 지원 챗봇을 개발한다고 가정해봅시다. 사용자가 “결제 오류”에 대해 질문하면, 결제와 관련된 예시를 제공하는 것이 효과적입니다. 반면 “배송 지연”에 대한 질문에는 배송 관련 예시가 더 적합합니다. Example Selector는 이러한 맥락적 요구를 충족하도록 설계되었습니다.
Example Selector의 주요 유형
LangChain은 다양한 상황에 맞춘 여러 Example Selector를 제공합니다. 아래에서 대표적인 유형을 살펴보겠습니다.
1. Semantic Similarity Example Selector
설명: 입력 쿼리와 예시 간의 의미적 유사성을 계산해 가장 관련성 높은 예시를 선택합니다. 이를 위해 일반적으로 임베딩 모델(예: OpenAI의 텍스트 임베딩)을 사용합니다.
작동 원리: 쿼리와 예시를 벡터로 변환한 뒤, 코사인 유사도(cosine similarity) 같은 메트릭을 활용해 유사도를 측정합니다.
사용 사례: 질문 답변 시스템, 문서 요약 등에서 입력과 의미적으로 가까운 예시가 필요한 경우.
장점: 맥락에 따라 동적으로 예시를 선택하므로 모델의 응답 품질이 향상됩니다.
예제 코드:
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain_ollama import OllamaEmbeddings
from langchain_chroma import Chroma
# 예시 데이터셋
examples = [
{"input": "결제 오류가 발생했어요", "output": "결제 오류는 보통 카드 정보가 잘못 입력되었거나 은행 문제일 수 있습니다."},
{"input": "배송이 늦어졌어요", "output": "배송 지연은 물류 상황에 따라 발생할 수 있으며, 추적 번호로 확인 가능합니다."}
]
# 임베딩 및 벡터 저장소 설정
embeddings = OllamaEmbeddings(model='exaone3.5')
selector = SemanticSimilarityExampleSelector.from_examples(
examples,
embeddings,
Chroma,
k=1 # 선택할 예시 개수
)
# 프롬프트 템플릿
prompt = FewShotPromptTemplate(
example_selector=selector,
example_prompt=PromptTemplate.from_template("입력: {input}\n출력: {output}"),
prefix="다음 질문에 답변하세요:",
suffix="\n질문: {query}",
input_variables=["query"]
)
# 프롬프트 생성
query = "결제 문제가 있어요"
formatted_prompt = prompt.format(query=query)
print(formatted_prompt)
다음 질문에 답변하세요:
입력: 결제 오류가 발생했어요 출력: 결제 오류는 보통 카드 정보가 잘못 입력되었거나 은행 문제일 수 있습니다.
질문: 결제 문제가 있어요
2. Length-Based Example Selector
설명: 예시의 길이를 기준으로 선택합니다. 예를 들어, 너무 긴 예시는 제외하거나 짧은 예시만 선택할 수 있습니다.
작동 원리: 예시 텍스트의 문자 수나 토큰 수를 계산해 조건에 맞는 예시를 필터링합니다.
사용 사례: 프롬프트 길이 제한이 있는 환경(예: 특정 LLM의 토큰 한도)에서 유용합니다.
설명: 유사성과 다양성을 동시에 고려해 예시를 선택합니다. 입력과 유사하면서도 서로 중복되지 않는 예시를 골라냅니다.
작동 원리: MMR 알고리즘을 사용해 유사도와 다양성 간 균형을 맞춥니다.
사용 사례: 여러 관점에서 답변을 제공해야 하는 경우(예: 창의적 글쓰기, 복잡한 문제 해결).
장점: 단일 주제에 치우치지 않고 다양한 예시를 활용 가능합니다.
예제 코드:
from langchain_community.vectorstores import FAISS
from langchain_core.example_selectors import MaxMarginalRelevanceExampleSelector
from langchain_core.prompts import FewShotPromptTemplate, PromptTemplate
# 1. 예제 데이터 정의
examples = [
{"input": "행복한", "output": "슬픈"},
{"input": "높은", "output": "낮은"},
{"input": "시끄러운", "output": "조용한"},
]
# 2. 예제 포맷 템플릿 설정
example_prompt = PromptTemplate(
input_variables=["input", "output"],
template="입력: {input}\n출력: {output}",
)
# 3. MMR 예제 선택기 초기화
example_selector = MaxMarginalRelevanceExampleSelector.from_examples(
examples,
embeddings,
FAISS, # FAISS 벡터 저장소
k=2, # 선택할 예제 수
)
# 4. FewShot 프롬프트 구성
mmr_prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
prefix="모든 입력의 반의어를 제공하세요:",
suffix="입력: {adjective}\n출력:",
input_variables=["adjective"],
)
# 5. 실행 예시
print(mmr_prompt.format(adjective="불안한"))
모든 입력의 반의어를 제공하세요:
입력: 시끄러운 출력: 조용한
입력: 높은 출력: 낮은
입력: 불안한 출력:
Example Selector 활용 팁
작업 맞춤화: 작업의 성격에 따라 적합한 Selector를 선택하세요. 단순한 작업에는 Length-Based를, 복잡한 맥락 이해가 필요한 경우에는 Semantic Similarity를 추천합니다.
예시 데이터 준비: Selector의 성능은 제공된 예시의 품질에 크게 의존합니다. 명확하고 구체적인 예시를 준비하는 것이 중요합니다.
k 값 조정: 선택할 예시 개수(k)를 조정해 프롬프트의 길이와 정보 밀도를 최적화하세요.
테스트와 반복: 다양한 쿼리로 Selector를 테스트하며 결과를 비교해 최적의 설정을 찾아보세요.
Example Selector 또 다른 예시
from langchain_chroma import Chroma
from langchain_ollama import OllamaEmbeddings
from langchain_core.example_selectors import MaxMarginalRelevanceExampleSelector, SemanticSimilarityExampleSelector
examples = [
{
"question": "스티브 잡스와 아인슈타인 중 누가 더 오래 살았나요?",
"answer": """이 질문에 추가 질문이 필요한가요: 예.
추가 질문: 스티브 잡스는 몇 살에 사망했나요?
중간 답변: 스티브 잡스는 56세에 사망했습니다.
추가 질문: 아인슈타인은 몇 살에 사망했나요?
중간 답변: 아인슈타인은 76세에 사망했습니다.
최종 답변은: 아인슈타인
""",
},
{
"question": "마이크로소프가 창립했을 때, 스티브 잡스는 몇살이었나요?",
"answer": """이 질문에 추가 질문이 필요한가요: 예.
추가 질문: 마이크로소프트 설립일은 언제인가요?
중간 답변: 마이크로소프트는 1975년 4월 4일 빌 게이츠와 폴 앨런에 의해 설립되었다.
추가 질문: 스티브 잡스는 몇 년에 태어났나요?
중간 답변: 스티브 잡스는 1955년 2월 24일에 미국 캘리포니아주 샌프란시스코에서 태어났습니다.
최종 답변은: 20살 (1975년 - 1955년)
""",
},
{
"question": "율곡 이이의 어머니가 태어난 해의 통치하던 왕은 누구인가요?",
"answer": """이 질문에 추가 질문이 필요한가요: 예.
추가 질문: 율곡 이이의 어머니는 누구인가요?
중간 답변: 율곡 이이의 어머니는 신사임당입니다.
추가 질문: 신사임당은 언제 태어났나요?
중간 답변: 신사임당은 1504년에 태어났습니다.
추가 질문: 1504년에 조선을 통치한 왕은 누구인가요?
중간 답변: 1504년에 조선을 통치한 왕은 연산군입니다.
최종 답변은: 연산군
""",
},
{
"question": "올드보이와 기생충의 감독이 같은 나라 출신인가요?",
"answer": """이 질문에 추가 질문이 필요한가요: 예.
추가 질문: 올드보이의 감독은 누구인가요?
중간 답변: 올드보이의 감독은 박찬욱입니다.
추가 질문: 박찬욱은 어느 나라 출신인가요?
중간 답변: 박찬욱은 대한민국 출신입니다.
추가 질문: 기생충의 감독은 누구인가요?
중간 답변: 기생충의 감독은 봉준호입니다.
추가 질문: 봉준호는 어느 나라 출신인가요?
중간 답변: 봉준호는 대한민국 출신입니다.
최종 답변은: 예
""",
},
]
# Vector DB 생성 (저장소 이름, 임베딩 클래스)
embeddings_model = OllamaEmbeddings(model="exaone3.5")
chroma = Chroma("example_selector", embeddings_model)
example_selector = SemanticSimilarityExampleSelector.from_examples(
# 여기에는 선택 가능한 예시 목록이 있습니다.
examples,
# 여기에는 의미적 유사성을 측정하는 데 사용되는 임베딩을 생성하는 임베딩 클래스가 있습니다.
embeddings_model,
# 여기에는 임베딩을 저장하고 유사성 검색을 수행하는 데 사용되는 VectorStore 클래스가 있습니다.
Chroma,
# 이것은 생성할 예시의 수입니다.
k=1,
)
question = "구글이 창립했을 때, 빌 게이츠는 몇살이었나요?"
# 입력과 가장 유사한 예시를 선택합니다.
selected_examples = example_selector.select_examples({"question": question})
from langchain_core.prompts.few_shot import FewShotPromptTemplate
from langchain_core.prompts import PromptTemplate
example_prompt = PromptTemplate.from_template(
"Question:\n{question}\nAnswer:\n{answer}"
)
prompt = FewShotPromptTemplate(
example_selector=example_selector,
example_prompt=example_prompt,
suffix="Question:\n{question}\nAnswer:",
input_variables=["question"],
)
from langchain_ollama import ChatOllama
llm_model = ChatOllama(model='exaone3.5', temperature=0)
# 체인 생성
chain = prompt | llm_model
answer = chain.invoke({"question": question})
print(answer.content)
이 질문에 대한 정확한 답변을 위해서는 몇 가지 추가 정보가 필요합니다:
구글 창립 날짜: 구글은 1998년 9월 6일에 창립되었습니다. 빌 게이츠의 생년월일: 빌 게이츠는 1955년 10월 28일에 태어났습니다.
언어 모델은 방대한 데이터로 훈련되지만, 특정 작업에 대해 최적의 응답을 생성하려면 맥락(context)과 의도(intent)를 명확히 제공해야 합니다. FewShotPromptTemplate은 작업의 예시를 몇 개 제공함으로써 모델이 사용자가 원하는 출력 형식을 이해하고, 이를 기반으로 일관성 있는 결과를 생성하도록 돕습니다.
예를 들어, 질문에 대한 답변을 생성하거나, 텍스트를 특정 스타일로 변환하는 작업을 수행할 때, 단일 지시(instruction)만 제공하는 것보다 몇 가지 입력-출력 쌍을 보여주는 것이 더 효과적일 수 있습니다. 이를 “few-shot learning”이라고 부르며, FewShotPromptTemplate은 이를 체계적으로 구현한 클래스입니다.
왜 FewShotPromptTemplate을 사용하는가?
맥락 제공: 모델이 작업의 의도를 더 잘 파악하도록 도와줍니다.
일관성 향상: 출력 형식을 예시로 명확히 정의하여 결과의 품질을 높입니다.
효율성: 긴 설명 대신 간단한 예시로 원하는 결과를 유도할 수 있습니다.
적응성: 다양한 작업에 맞게 예시를 조정하여 유연하게 사용할 수 있습니다.
FewShotPromptTemplate의 기본 구조
LangChain의 FewShotPromptTemplate은 다음과 같은 구성 요소로 이루어집니다:
examples: 모델에 제공할 입력-출력 예시 리스트.
example_prompt: 각 예시를 형식화하기 위한 프롬프트 템플릿.
prefix: 프롬프트의 시작 부분으로, 작업에 대한 설명이나 지시사항을 포함.
suffix: 프롬프트의 끝 부분으로, 사용자의 실제 입력값을 삽입하는 위치를 지정.
input_variables: 사용자 입력으로 채워질 변수 이름.
example_separator: 각 예시 사이를 구분하는 문자열(기본값은 \n).
이제 이 요소들을 하나씩 살펴보고, 실제 코드를 통해 사용법을 익혀보겠습니다.
예제: 감정 분류기 구현하기
FewShotPromptTemplate을 사용해 텍스트의 감정을 분류하는 간단한 예제를 만들어 보겠습니다. 여기서는 긍정(positive), 부정(negative), 중립(neutral)으로 감정을 분류하는 작업을 수행합니다.
1. 필요한 모듈 임포트
먼저 LangChain에서 필요한 모듈을 가져옵니다.
from langchain.prompts import FewShotPromptTemplate, PromptTemplate
2. 예시 데이터 준비
모델에 제공할 입력-출력 쌍을 정의합니다.
examples = [
{"text": "이 영화 정말 재미있어요!", "sentiment": "positive"},
{"text": "음식이 너무 맛없어서 실망했어요.", "sentiment": "negative"},
{"text": "오늘 날씨가 평범하네요.", "sentiment": "neutral"}
]
다음 텍스트의 감정을 분류하세요. 감정은 positive, negative, neutral 중 하나로 선택합니다.
입력: 이 영화 정말 재미있어요! 출력: positive
입력: 음식이 너무 맛없어서 실망했어요. 출력: negative
입력: 오늘 날씨가 평범하네요. 출력: neutral
입력: 새로운 프로젝트가 기대돼요! 출력:
이 프롬프트를 언어 모델에 전달하면, 모델은 주어진 예시를 바탕으로 “positive”라는 출력을 생성할 가능성이 높습니다.
고급 활용: 동적 예시 선택
고정된 예시 대신, 입력에 따라 관련성 높은 예시를 동적으로 선택하고 싶다면 LangChain의 SemanticSimilarityExampleSelector를 사용할 수 있습니다. 이는 입력과 유사한 예시를 벡터 유사도 기반으로 선택합니다.
예제: 동적 감정 분류기
from langchain.prompts.example_selector import SemanticSimilarityExampleSelector
from langchain_community.vectorstores import FAISS
from langchain_ollama import OllamaEmbeddings
# 임베딩 모델 설정 (OpenAIEmbeddings는 API 키 필요)
embeddings = OllamaEmbeddings(model='exaone3.5')
# 예시 벡터화 및 저장
selector = SemanticSimilarityExampleSelector.from_examples(
examples,
embeddings,
FAISS,
k=2 # 가장 유사한 2개의 예시 선택
)
# 동적 FewShotPromptTemplate 생성
dynamic_prompt = FewShotPromptTemplate(
example_selector=selector,
example_prompt=example_prompt,
prefix="다음 텍스트의 감정을 분류하세요. 감정은 positive, negative, neutral 중 하나로 선택합니다.\n\n",
suffix="\n입력: {input}\n출력:",
input_variables=["input"],
example_separator="\n\n"
)
# 테스트
print(dynamic_prompt.format(input="이 책 정말 감동적이에요!"))
다음 텍스트의 감정을 분류하세요. 감정은 positive, negative, neutral 중 하나로 선택합니다.
입력: 이 영화 정말 재미있어요! 출력: positive
입력: 음식이 너무 맛없어서 실망했어요. 출력: negative
입력: 이 책 정말 감동적이에요! 출력:
이 경우, 입력과 의미적으로 가까운 예시(예: “이 영화 정말 재미있어요!”)가 선택되어 모델의 성능을 더욱 향상시킬 수 있습니다.
주의사항 및 팁
예시의 품질: 예시는 명확하고 작업의 의도를 잘 반영해야 합니다. 모호한 예시는 모델을 혼란스럽게 할 수 있습니다.
예시 개수: 너무 많은 예시는 토큰 한도를 초과하거나 모델을 과부하로 만들 수 있으니, 보통 3~5개가 적당합니다.
형식 일관성: example_prompt와 suffix의 형식이 일치해야 모델이 출력을 예측하기 쉽습니다.
FewShotPromptTemplate은 LangChain에서 언어 모델의 잠재력을 극대화하는 강력한 도구입니다. 적은 예시로도 모델이 작업을 학습하고, 일관성 있는 출력을 생성하도록 유도할 수 있습니다. 이 챕터에서 다룬 기본 예제와 고급 활용법을 바탕으로, 여러분만의 창의적인 프롬프트를 설계해보세요.
최신 대규모 언어 모델(LLM)의 강력함은 방대한 데이터로 사전 학습된 결과이지만, 특정 작업에 대해 모델을 즉각적으로 적응시키는 데는 한계가 있습니다. 이때 “퓨샷 프롬프트(Few-Shot Prompting)”는 최소한의 예시만으로도 모델이 새로운 작업을 수행하도록 유도하는 강력한 방법론으로 주목받고 있습니다. LangChain 프레임워크에서는 이러한 퓨샷 프롬프트 기법을 체계적으로 활용할 수 있는 도구와 구조를 제공합니다.
퓨샷 프롬프트는 언어 모델에게 소수의 입력-출력 예시를 제공하여, 추가적인 학습 없이도 특정 작업을 수행할 수 있도록 하는 프롬프트 엔지니어링 기법입니다. 이는 제로샷(Zero-Shot)과 풀샷(Full-Shot) 사이에 위치하며, 모델이 맥락을 이해하고 일반화된 패턴을 학습하도록 돕습니다. 예를 들어, 텍스트 분류, 질문 응답, 번역 등 다양한 작업에 대해 몇 개의 예시만으로도 모델이 적절한 출력을 생성하게 할 수 있습니다.
퓨샷 프롬프트의 작동 원리
예시 제공: 입력과 기대 출력의 쌍을 명시적으로 제공합니다.
맥락 학습(In-Context Learning): 모델이 주어진 예시를 통해 작업의 패턴을 파악합니다.
일반화: 새로운 입력에 대해 학습된 패턴을 적용하여 결과를 생성합니다.
LangChain에서는 이러한 과정을 체계화하여, 복잡한 작업에서도 일관성 있고 정확한 결과를 얻을 수 있도록 지원합니다.
퓨샷 프롬프트의 장점
효율성: 대량의 데이터로 모델을 재학습시킬 필요 없이 소수의 예시만으로 작업 수행 가능.
유연성: 다양한 작업에 적용 가능하며, 예시를 조정해 결과를 즉각적으로 튜닝 가능.
비용 절감: 파인튜닝(Fine-Tuning) 대비 낮은 컴퓨팅 자원 소모.
주의점 및 최적화 팁
예시의 품질: 예시는 명확하고 대표적이어야 하며, 작업의 의도를 잘 반영해야 합니다.
예시 개수: 너무 적으면 일반화가 어렵고, 너무 많으면 모델의 처리 한계를 초과할 수 있습니다 (보통 3~5개 권장).
형식 일관성: 입력과 출력의 형식을 일관되게 유지하여 모델의 혼란을 최소화하세요.
복잡한 작업: 복잡한 작업의 경우, 예시와 함께 명확한 지침(prefix)을 추가로 제공하는 것이 좋습니다.