
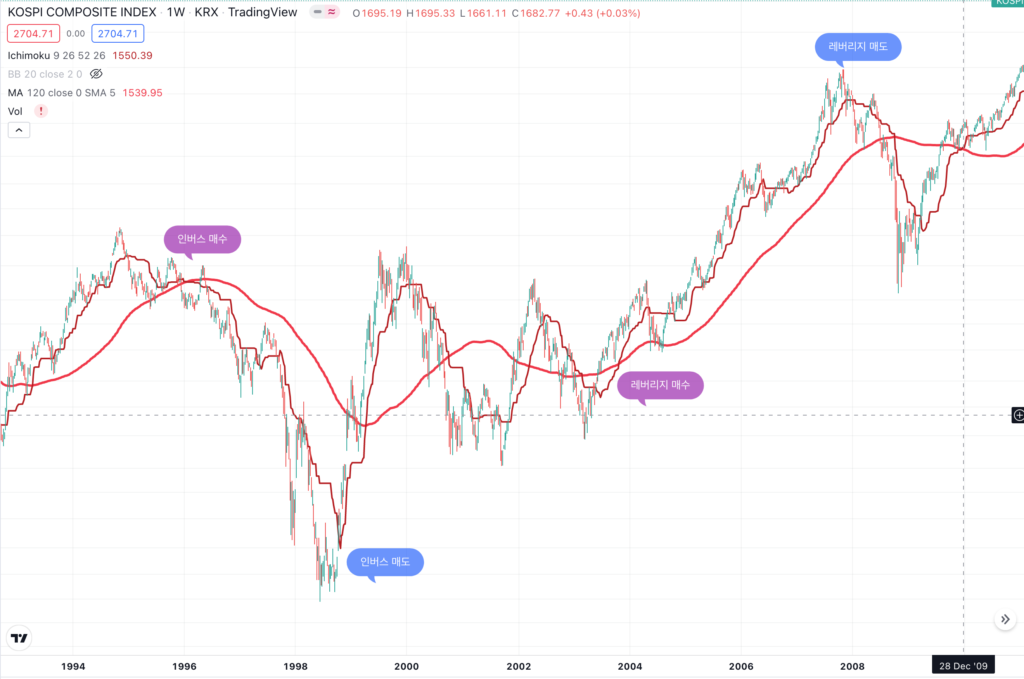
- Leveraged Equity ETF List
- Inverse Equity ETF List
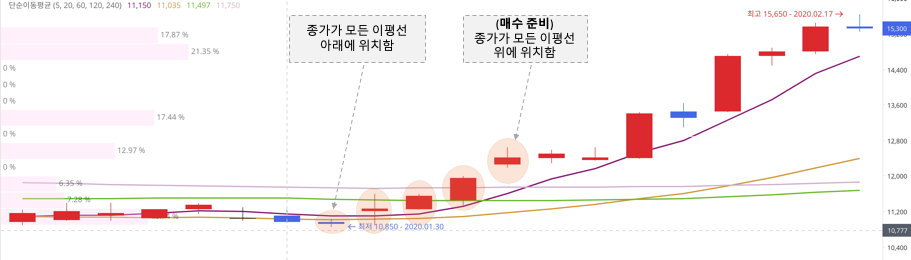
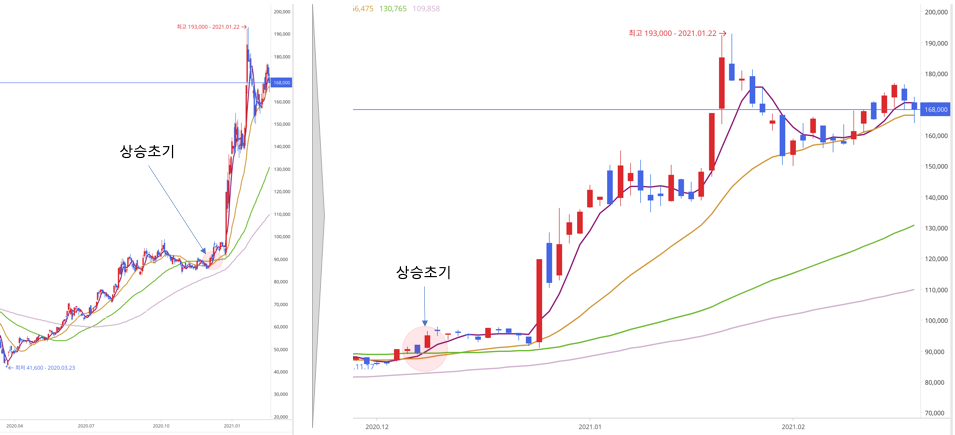
캔들의 종가 5, 20, 60, 120 이동평균선보다 아래에 위치해 있다가
10일이내로 모든 이동평균선을 상향 돌파한다면, 적극 매수를 시도한다.
이동 평균의 정배열이란, 짧은 이동평균부터 위에 위치한 상태이다.
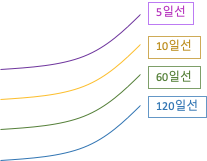
흔히 주가가 상승할 때 나타나는 현상이다.
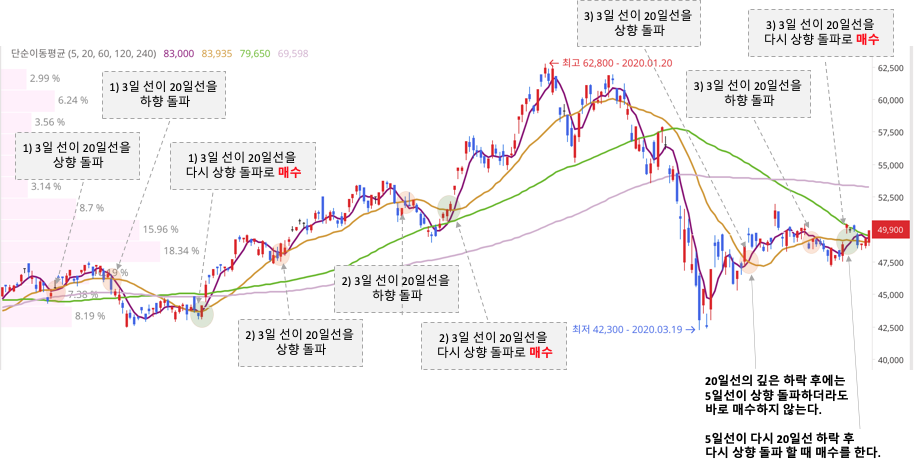
하락 추세의 주식이 상승 추세로 변하면서 역배열인 이평선이 정배열이 되는 시점을 골든크로스 라고 한다. 일반적으로 이평선이 정배열 (상승 추세) 이 되었을때 매매를 해야 한다.
특히 이평선의 정배열 초기, 골든크로스를 초기에 잡으면 강하게 상승을 해주는 모습을 많이 보여주기 떄문에 이 정배열 초기를 잘 탐지해서 매수를 해야한다.
1. 분석되지 않은 종목은 매수하지 않는다.
2. 대표지수 (예, kospi, dow, nasdaq 등) 의 월별 stochastic이 상향 중일 때는 leverage, 하향 중일 때는 inverse에 집중한다.
<1단계: C언어 기반의 mecab 설치>
C 드라이브에 mecab 폴더를 만든다. (“C:/mecab”)
mecab-ko-msv를 윈도우 버전에 따라 32bit (mecab-ko-msvc-x84.zip) / 64bit (mecab-ko-msvc-x64.zip)선택하여 다운로드한 후 압축을 푼다.
<2단계: mecab 사전 철치>
사전 링크에서 mecab-ko-dic-msvc.zip 기본 사전을 다운로드받아서 (“C:/mecab”)에 압축을 푼다.
<3단계: python용 mecab 설치>
– 해당 경로에서 버전에 맞는 라이브러리를 다운로드 한다.
(예시, 64bit window에 3.6 파이썬은 mecab_python-0.996_ko_0.9.2_msvc-cp35-cp35m-win_amd64.whl를 다운로드 받는다.)
– 다운로드 받은 라이브러리를 설치한다.
> pip install mecab_python-0.996_ko_0.9.2_msvc-cp35-cp35m-win_amd64.whl
for day in data:
query = {"query": {
"range": {
"day": {
"gte":day,
"lte":day,
}}}}
result = es.delete_by_query(index='content', doc_type='_doc', body=query)
item = data[day]
doc = {"day": day,
"p0": item['p0'],
"p1": item['p1'],
"p2": item['p2'],
"p3": item['p3'],
"p4": item['p4'],
"p5": item['p5'],
"p6": item['p6'],
"p7": item['p7'],
"@timestamp": edate + 'T00:00:00.0Z'}
es.index(index="content", doc_type="_doc", body=doc)
data =
{
"2020-07-13":{
"p0":7,
"p1":0,
"p2":0,
"p3":40,
"p4":7,
"p5":0,
"p6":7,
"p7":0
},
"2020-07-14":{
"p0":6,
"p1":0,
"p2":0,
"p3":43,
"p4":4,
"p5":0,
"p6":2,
"p7":0
}
}
$ service filebeat start 혹은 $ ./filebeat -c filebeat.yml -e
# 사용할 필터중에서 bundle 로 제공되지 않는 alter 설치 $ ./bin/logstash-plugin install logstash-filter-alter Validating logstash-filter-alter Installing logstash-filter-alter Installation successful
$ nohup ./bin/logstash -f logstash.conf > /var/log/logstash/logstash.out
참고) tinydb document: https://buildmedia.readthedocs.org/media/pdf/tinydb/latest/tinydb.pdf
# json 테스트 입력 파일
{
"_default":{
"1": {"type": "tag", "name": "A0", "scopeKind": "struct1"},
"2": {"type": "tag", "name": "A0", "scopeKind": "struct2"},
"3": {"type": "tag", "name": "A0", "scopeKind": "struct3"},
"4": {"type": "tag", "name": "A1", "scopeKind": "struct4"},
"5": {"type": "tag", "name": "A1", "scopeKind": "struct5"}
}
}
from tinydb import TinyDB, Query
import pprint
pp = pprint.PrettyPrinter(indent=4)
db = TinyDB('./test_json_1.dic')
filter = Query()
# 항목 제거
db.remove(filter.scopeKind == 'struct4')
# 항목 업데이트
db.update({'scopeKind': 'struct7'}, filter.name == 'A1')
# 항목 삽입
db.insert({ 'name': 'user', 'permissions': [{'type': 'read'}]})
# 출력 확인
pp.pprint(db.all())
# json 테스트 출력 파일
[ {'name': 'A0', 'scopeKind': 'struct1', 'type': 'tag'},
{'name': 'A0', 'scopeKind': 'struct2', 'type': 'tag'},
{'name': 'A0', 'scopeKind': 'struct3', 'type': 'tag'},
{'name': 'A1', 'scopeKind': 'struct7', 'type': 'tag'},
{'name': 'user', 'permissions': [{'type': 'read'}]}]
from tinydb import TinyDB, Query
import pprint
pp = pprint.PrettyPrinter(indent=4)
db = TinyDB('./test_json_2.dic')
filter = Query()
# 항목 제거
db.remove(filter.word == "you've")
# 항목 업데이트
db.update({'tag': 'NNP'}, filter.word == '예')
# 항목 삽입
db.insert({'word': 'zzz', 'tag':'NNG'})
# 출력 확인
data = db.all()
pp.pprint(data)
# json 테스트 입력 파일
{
"_default":{
"1": {"word":"예","tag":"NNG"},
"2": {"word":"한","tag":"MM"},
"3": {"word":"다음","tag":"NNG"},
"4": {"word":"돈","tag":"NNG"},
"5": {"word":"사","tag":"NNG"},
"6": {"word":"아","tag":"NNG"},
"7": {"word":"you've","tag":"NNG"}
}
}